從零打造前端效能監控系統 | WebConf Taiwan 2023 逐字稿
12 Aug 2023「從零打造前端效能監控系統」WebConf Taiwan 2023 逐字稿,歡迎搭配投影片與範例一同閱讀。
1

大家好,我是 Summer,今天想跟大家分享的是「從零打造前端效能監控系統」這個主題。
2

我是 Summer,我是前端工程師。
「Summer。桑莫。夏天」是我的部落格,主要是前端技術的分享。
「打造高速網站,從網站指標開始!全方位提升使用者體驗與流量的關鍵」這是我寫的書,如果大家對網頁前端效能有興趣,歡迎找來看看。
下面的連結是我的 FB、Twitter 和 Email,歡迎交流!
(2023/09/02 更新) 歡迎使用 Instagram 與我交流!
3
我曾經做過一個 project,這個 project 會從後端讀取一筆很大的資料,然後在前端經過一連串複雜的運算後,顯示在畫面上。 概念上如這張圖所示,會畫出很複雜的流程圖,並且根據使用者的操作而有不同的顯示。
通常在這種狀況下,會遇到幾個問題:
- (1) 首先,從後端拿一筆大量的資料,意味著有大量的網路傳輸時間;
- (2) 再來,大量的資料運算,會大量的佔用 main thread 太多時間,造成 long task,而 long task 就會 block UI 的顯示。
因此,對使用者來說,可能會遇到在畫面上 loading icon 出現很長的一段時間,或是圖片很慢才出現,或是每做一個動作,就會感覺卡卡的,內容很慢才顯示出來、很慢消失,這樣的狀況就是我們說的,載入或是渲染效能很差的狀況。
4

這樣該怎麼辦呢?有沒有辦法改進呢?
當然有很多方法改進,像是…
- 關於大量計算,我們可以把計算的工作切小方便做 context switch,或是丟到 web worker 來做計算,減少 main thread 的負擔。
- 關於大量的網路傳輸,我們可以先做資料或圖片或程式碼壓縮,減少網路傳輸的量;或是做 preload、prefetch、lazy loading 等方式預先取得資源,讓使用者早點看到畫面,其他的之後再慢慢用非同步的方式載入。
這些都可以改善剛剛遇到的效能問題,讓我們的 UI 變得更快更順暢。
5

不過呢,如果我們都是在遇到問題的時候才開始解決,那反應真的就太慢了。
關於我們這次會遇到這個效能瓶頸的問題,之前已經修過一次了,會再次發生這樣的狀況,大概可以總結以下幾個原因:
- 第一,最根本的原因是,我們沒料到客戶的資料量有這麼大。
- 第二,我們沒有把這個問題當成每次出 build 的時候,一定會測試的項目之一。我們一定會測 bug,並且寫成 unit test、integration test 或 e2e test 的自動化測試的 test case,但我們沒有在每次出 build 前做這樣的效能測試,更別說寫成自動化的測試項目之一。所以當我們做改版、修 bug 之後,可能新增了功能,或是解決了問題了,但效能的問題可能又會產生了。
大多數的狀況下我們可能都是在追求完善功能,但很多東西是可以做得更好的,像是效能、SEO、互動體驗這些。
反反覆覆的修正問題又產生問題,是很煩人的,而我相信我可以做得更好,只是要怎麼做呢?
6

這樣重複出現問題實在不是一個好的現象,如果要我想一個好的解法,那我會希望這個解法可以達成以下幾個目標:
- 第一,我希望可以檢測大量資料,顯然先前的資料量不夠大。
- 第二,我希望可以自動檢測每一個 build,才不會讓我們改 bug 或新增修改功能時,不小心改壞掉。
- 第三,我希望他有點預知能力,很多事情我們是預料不到的,但是會有「可能會有問題」的徵兆。這個徵兆會告訴我們必須要能先做些調整。而且在檢測之後,如果有潛在的問題,要能通知我。
- 第四,我希望這個方法足夠簡單、容易實作,不增加開發負擔,不必用酷炫的工具,或是能用目前專案當中現有的機制,做一些調整,就能達到很棒的效果,這樣的解法才能融合在日常工作中。太難太複雜或是更動太大的往往會增加開發者的負擔或是提高團隊推廣的門檻而難以實行。
7

在開始正題之前,我們來談談怎麼衡量效能。
提到效能,通常會用兩個方式來衡量:
- 第一個是載入效能 loading performance,是指頁面載入時,是否能很快看到畫面、很快能互動,以及板塊是否能流暢的顯示。
- 第二個是渲染效能 rendering performance,是指在畫面更新過程中,是否足夠順暢、不卡頓。
如果能好好的優化以上兩個方向,絕對能帶給使用者良好的體驗。
這樣講很抽象,我們怎麼知道自己有朝這些方向邁進呢?那就需要一些指標,我們在改善的同時,用這些指標衡量,來幫助我們了解到底有沒有走在正確的道路上。指標就像是北極星,而衡量指標的工具就是像指南針。想要走到目的地,光看著星星是不夠的,在每一步當中都必須有工具幫忙告訴我們,這樣的方向是正確的嗎?避免我們在實作中迷失、忘了自己在幹嘛。
8

圖片來源:Core Web Vitals
關於 loading performance 的測量工具和指標,我們通常會利用 Chrome DevTools 和 Lighthouse 來檢測 web vitals,而在這裡我們看到的是核心的指標 LCP、FID 和 CLS。
- LCP 是指畫面上最大面積的元素出現的時間,它能告訴我們是否能很快看到畫面的重點,使用者是否能很快的確定這個網頁的內容是他們想要的。LCP 通常會是首圖/大圖出現的時間點。
- FID 是指使用者第一次操作網頁,直到瀏覽器能對此互動做出回應的時間差,它能告訴我們網頁是否能很快的互動。畢竟只能看、不能用的網頁是非常糟糕的。
- CLS 是累計版位位移,是指在頁面的整個存活期間,每個可見元素位移分數的總和。它能告訴我們在視覺上是否能有舒適的體驗。我們常常遇到網頁載入過程中因為圖檔加入而不斷推移網頁其他板塊,導致我們點錯東西或是眼花撩亂,這樣就是很惱人的。我們當然會希望網頁的板塊是穩定的,能讓使用者好好的瀏覽和操作。
9

關於 rendering performance,通常會用是否達到 60fps,或是是否有 long task 來作為衡量標準。
- fps 是指畫面播放速率,fps 越大,畫面顯示就愈平滑、愈流暢。
- long task 是指執行超過 50ms 的工作,佔用 main thread 超過 50ms 意味著可能會有效能問題,必須優化。
這是因為我們從實驗得出,使用者與網頁互動後,最多只能等待 100ms,等待超過 100ms 使用者就會感到不耐煩。 為了讓瀏覽器能在 100ms 內給予回應,我們必須讓瀏覽器在處理日常工作或手上還有事情要做的狀況當中,仍能保持某個程度上的空閒,因此我們會希望每個 task 不要執行超過一半的容忍時間,也就是不要超過 50ms,至少能留一半的 buffer 給瀏覽器能再次接收使用者的互動。
在檢測 rendering performance 上,工具上會利用 Chrome DevTools 來測量 task 的執行時間,或用 why-did-you-render 或直接 console timestamps 來計算元件 re-render 的次數。
10

看完怎麼衡量效能之後,來看衡量效能的環境。
在資料採集的環境上,分為模擬和實地兩種狀況。意思就是,利用模擬的方式來採集到的資訊,或是追蹤真實使用者操作來得到的資訊兩種。差別在於,在開發時我們利用模擬的方式來重現問題、解 bug;而上線之後這些真實的使用者的資訊能讓我們驗證是否真的有解決問題,或是發掘潛在的問題,兩者缺一不可。
在衡量的工具上,我們熟知的 Lighthouse 和 Chrome DevTools 是屬於模擬的,而 Sentry 或是 New Relic 則是實地的。
11
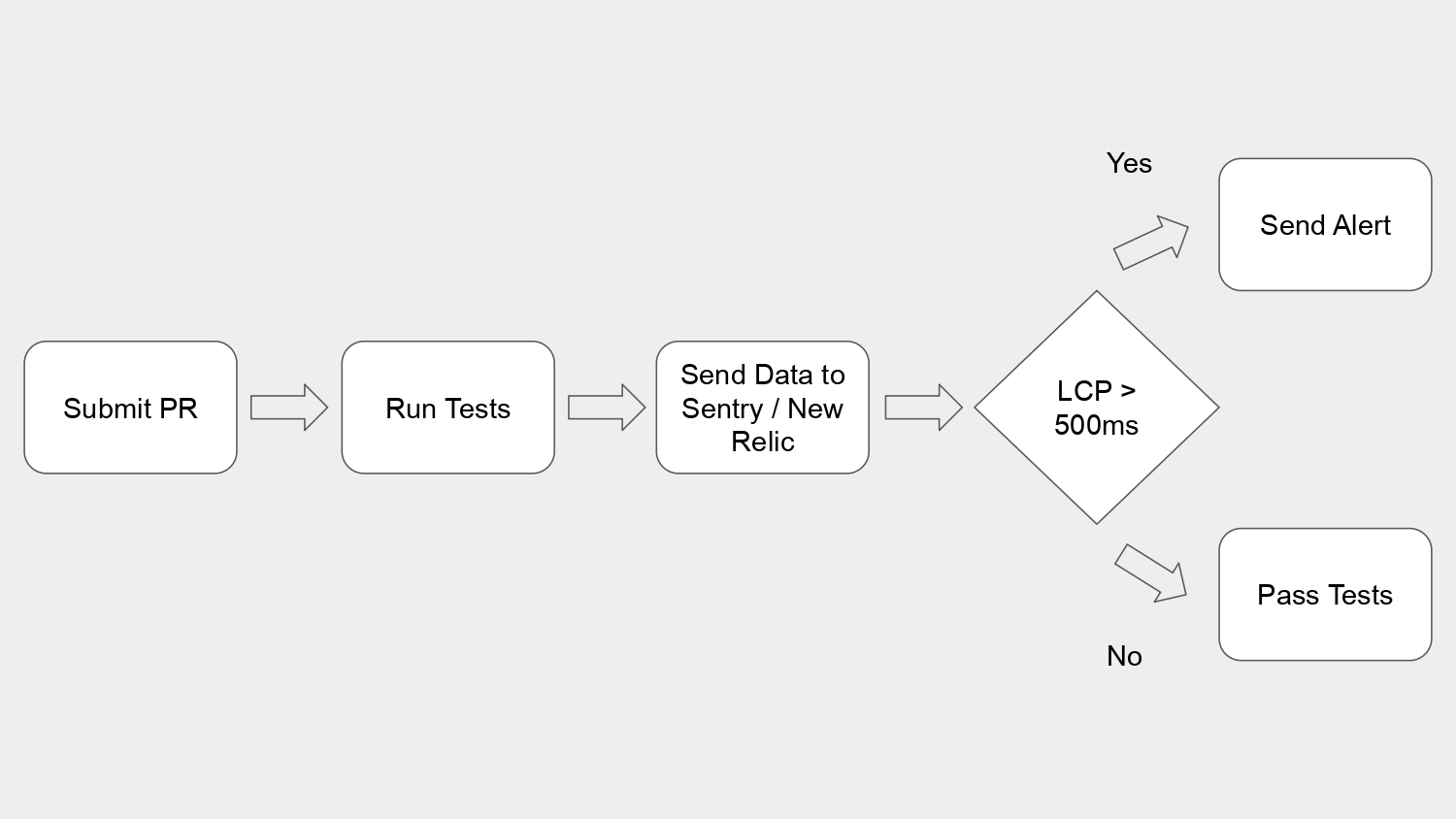
不諱言的,當我訂這次分享的題目「從零打造前端效能監控系統」的時候,真的覺得有點大,大家可能會猜想是不是要手刻一個系統,能收資料、有 dashboard 還能做 load balance,但是我想跟大家分享的是怎麼做一個架構,或說是工作流程。
這張投影片要來聊的架構,同時也會回應前面我想達成的四個目標:
- 第一,關於大量的資料,我希望這個測試機制能讓我們隨心所欲導入大量的資料。Cypress 可以幫我們丟進去很大量的資料而不用再加工處理,非常方便。
- 第二,我們可以利用 end-to-end testing 來幫我們做自動化測試,包含畫面載入、UI 操作,在這裡用的就是剛剛提到的 Cypress。Cypress 的 E2E test script 可用 mock data 或線上產品,mock data 可用來測試資料量極大的狀況。不過,使用 mock data 來做 E2E test 基本上是不符合這類型測試的意義的,但在此是為了排除干擾測試的因素,像是網路不穩等,而能單純比較前端或說是瀏覽器的這個部份。 再來,為了要自動檢測每一個 build,我們利用 CI/CD 幫我們在提 PR 時 trigger 測試,這樣就能自動檢測每一個 build 的效能,才不會讓我們改壞。
- 第三,關於預知能力,這要靠我們自己設定一些 threshod,當超過這個 threshold 就表示有危險,要通知我們,像是在這個範例就是當 LCP 測試到超過 500ms 時要做通知。而 Sentry 或 New Relic 都是可以蒐集 issue 或 performance data 的平台。它們的功能很多,在這兒不一一描述。在這流程中由於是把資料送到 Sentry 或 New Relic,因此就是用它們的 alert 功能了,這些都是可以換成其他實作方式的。說明一下,LCP 超過 500ms 就要通知這樣設定的條件是比較嚴格的,照理來說 LCP < 2.5 秒即是良好,但現在大多使用者的網路和設備條件都很不錯,尤其在桌機 + WIFI 的狀況下更是如此,等待 0.5 秒應該是許多人耐心的極限了,因此在這裡設定若超過 0.5 秒還無法讓人看到有個 loading icon 就必須來查查看是不是有什麼問題。
- 第四,要足夠簡單,在這裡我提出的方法是利用 Cypress + GitHub Actions + Sentry,這應該是足夠簡單的,因為我們都會寫測試也都會用自動化測試的方式幫我們測試,蒐集資訊、dashboard 呈現和通知也是現成 Sentry 的工具,這樣這個方法足夠簡單、容易實作,就不會增加開發負擔,才能融合在日常工作中。
12

提到效能測試,就一定要來聊聊行動裝置的部份。
Cypress 可以針對不同的 viewport 來模擬測試不同大小的裝置、不同版面的狀況,像是 touch 和 scroll 等動作的模擬。
再來,前面提到我們想要排除網路狀況,只比較前端的部份,但若我們真的想要知道不同網路狀況下,會有怎樣的結果,要怎麼做呢?
Cypress 可以在 intercept 這個指令裡面設定 setTimeout 或 wait 作為等待機制,模擬網路很慢的狀況。
順道一提,Sentry 和 New Relic 除了可蒐集 mobile web 的資訊外,還提供 app 的 most slow frames 和 most frozen frames 的檢測機制以供參考。
13
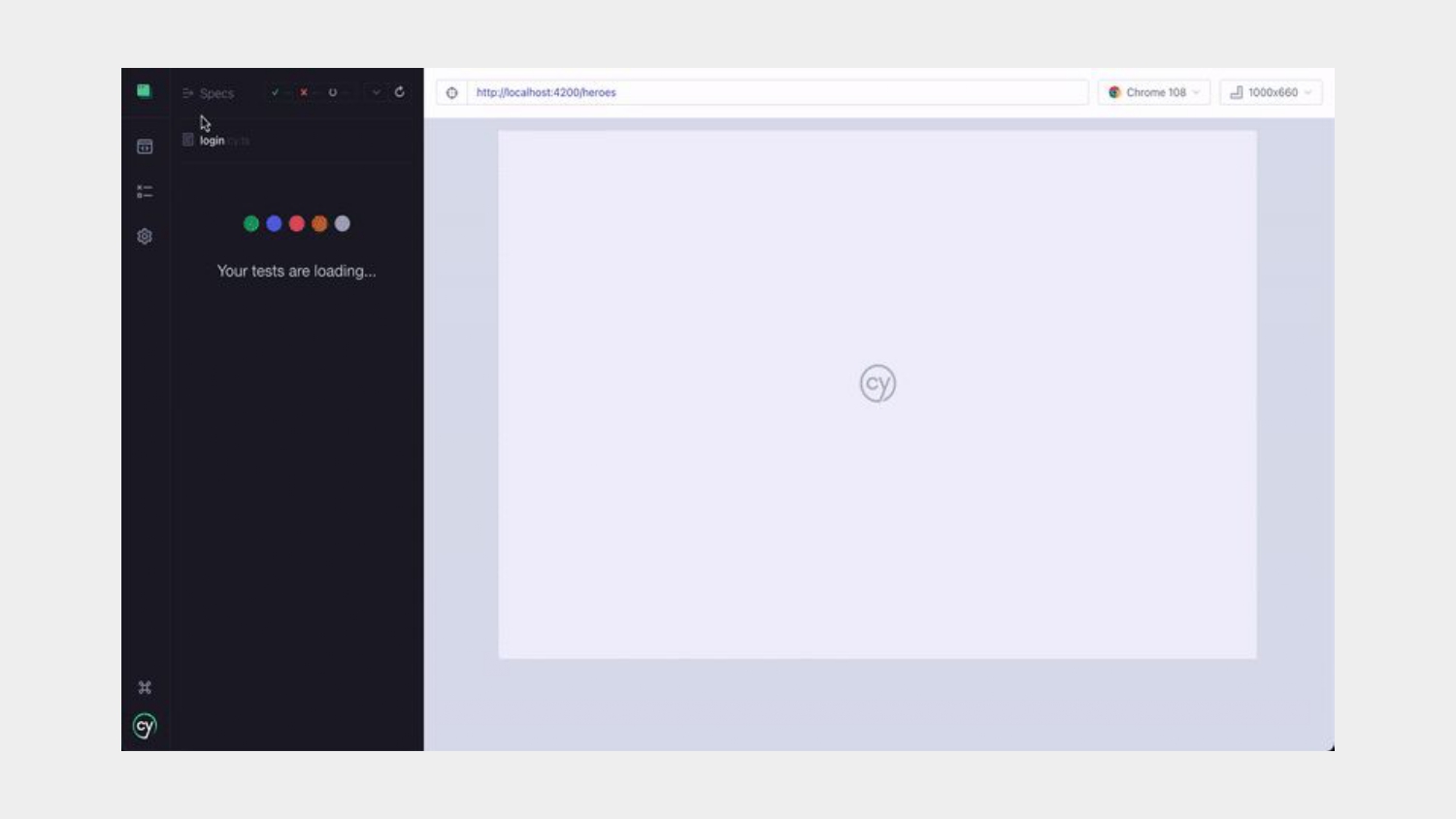
來簡單介紹一下 Cypress,在這裡我們會用 Cypress 來做自動化測試。
Cypress 是一個非常優秀的測試框架,在我的使用經驗來看,它和其他測試框架最不一樣的地方,就是它可以即時瀏覽或是重現目前測試到哪個 case 以及 UI 的狀況,而且它可以直接丟入 mock data 而不用再做額外的處理,非常方便。
下面我們來看個實例。
14
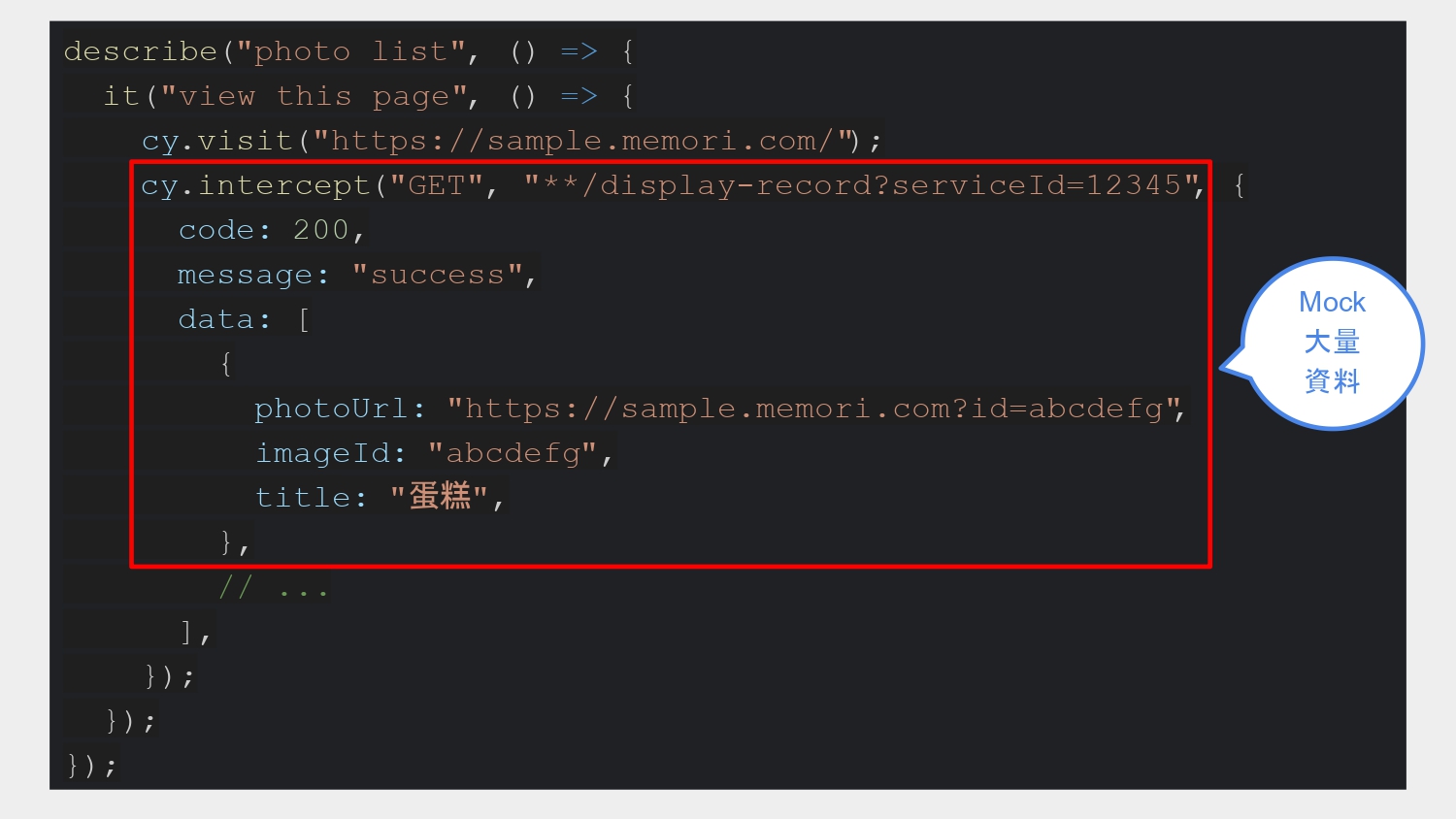
我們來看一個 Cypress 寫測試的例子,我們可以用 visit 這個指令來瀏覽某個網頁,然後用 intercept 指令來 mock API 的 repsonse。
describe("photo list", () => {
it("view this page", () => {
cy.visit("https://sample.memori.com/");
cy.intercept("GET", "**/display-record?serviceId=12345", {
code: 200,
message: "success",
data: [
{
photoUrl: "https://sample.memori.com?id=abcdefg",
imageId: "abcdefg",
title: "蛋糕",
},
// ...
],
});
});
});
也就是說,我們利用 e2e testing 來模仿使用者操作畫面,然後蒐集這些資料來幫我們衡量效能好不好。我們會固定在一台機器上跑這個 script 而不是在開發者的 local 跑,就可以有一個統一的衡量標準。
注意,由於我們想要做效能測試,這邊的 mock data 就可以放非常非常多筆。
15
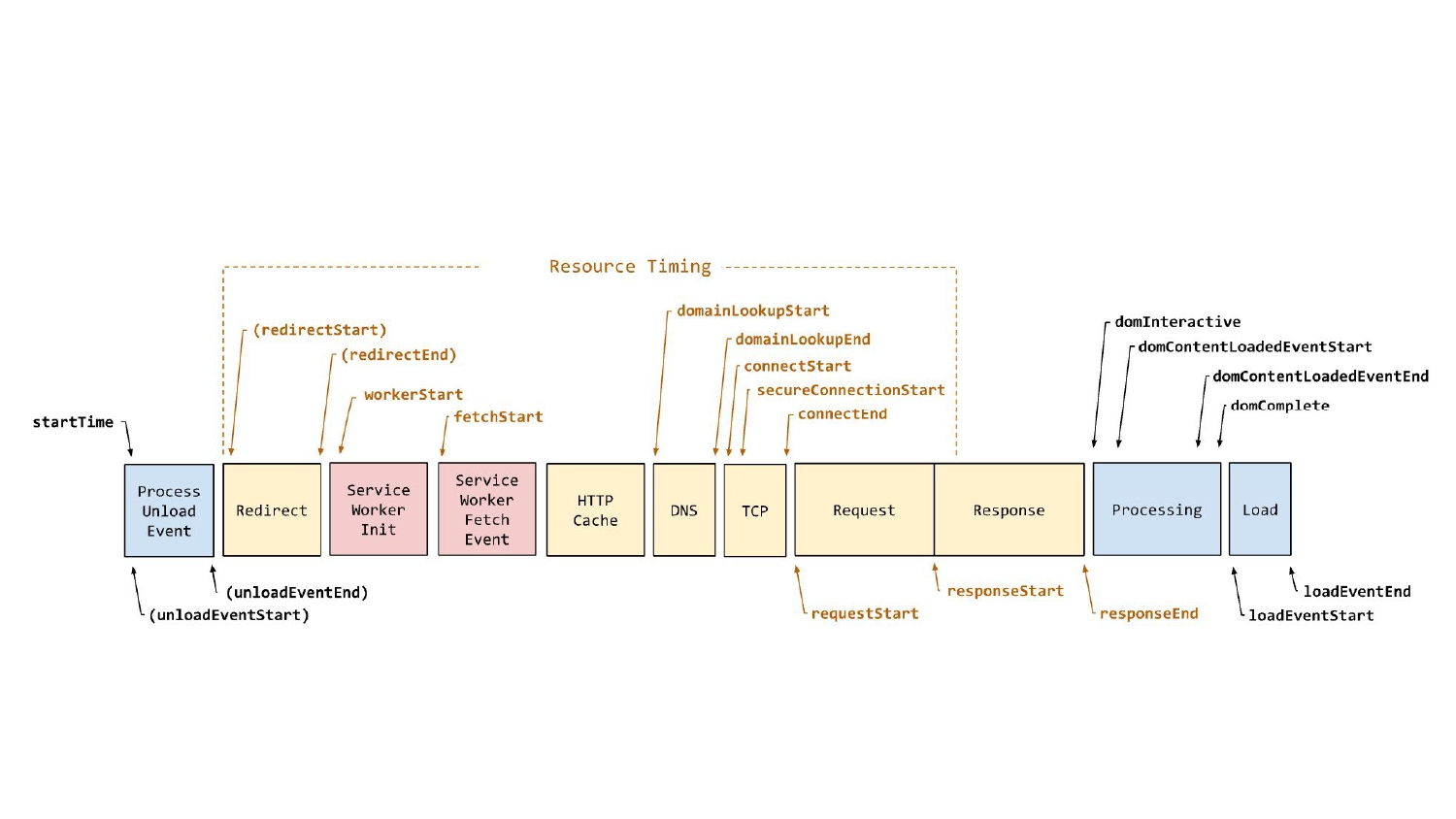
圖片來源:PerformanceNavigationTiming
知道了要怎麼模擬 UI 的操作之後,接下來我們要看怎麼蒐集資料。
前面提到我們會依照 loading performance 或 rendering performance 不同的狀況來蒐集不同指標的值,在這裡先來看我們怎麼蒐集 loading performance 的 LCP、FID 和 CLS。
這張投影片是 MDN 的 PerformanceNavigationTiming 文件當中的時序圖,能告訴我們在頁面載入過程中發生了什麼事。我們沒有辦法直接取得 LCP、FID 和 CLS,因為這些指標的值是經由計算得到的,但很幸運的我們可以透過 PerformanceObserver 來幫我們取得。
備註:歡迎參考這兩篇文章-在瀏覽器輸入網址並送出後,到底發生了什麼事?、從內部來看瀏覽器到底在做什麼?(Inside look at modern web browser)。
16

像是指標之一的 FCP (First Contentful Paint),FCP 是指畫面上第一個的元素出現所花的時間,它能告訴我們是否能很快看到畫面,使用者是否能很快的確定網頁有反應。通常 FCP 會是 loading icon 出現的時間。
如程式碼所示,我們想要知道 FCP 的值是多少,就可以利用 PerformanceObserver 取得。其他的 metrix 像是 LCP、FID 和 CLS 也可以用同樣的方式取得。
const observer = new PerformanceObserver(function(list, obj) {
const entries = list.getEntries();
entries.forEach(item => {
if (item.name === 'first-contentful-paint') {
console.log(item);
}
})
});
observer.observe({type: 'paint'});
PerformancePaintTiming {name: 'first-contentful-paint', entryType: 'paint', startTime: 1142.0999999977648, duration: 0}
不過在這裡,我們只是要知道原理即可,在蒐集資料的過程中,我們並不需要自己手刻這些工具,因為 Sentry 的 JavaScript SDK 都幫我們做好了,我們只要在專案中安裝和載入 SDK,就可以透過 SDK 幫我們蒐集資料。
備註:指標總整理。
17

知道怎麼蒐集資料後,接著就要利用 Sentry 來整理、呈現資料,並且依照我們設定的 threshold 來通知測試結果到底好不好。
Sentry 是一個追蹤錯誤和監控效能平台,它可以幫忙開發團隊迅速發現和解決問題,協助持續改善軟體品質和使用者體驗。
那我們要如何利用 Sentry 來解決問題呢?在這裡分為兩個 case ~
- 第一個 case 是遇到確切的問題了,而我們需要更多資訊來確認問題所在,並在之後驗證問題是否已被解決。
- 第二個 case 類似 routine 工作,目的是希望能幫我們找出潛在的效能問題來做 enhance。
18

我們來看個例子,順便小小的打個廣告。
不知道大家有沒有這樣的經驗…和朋友出去玩,想看彼此拍的照片,就必須要傳檔案或是分享相簿,非常麻煩、又沒有隱私,收檔案還佔手機空間。 或是,在活動或婚禮上,想要播放大家的過往照片,或是使用拍貼機加上即時瀏覽功能,這種服務都超級貴的,辦活動辦婚禮超花錢,這個錢能不能省下來?
如果你有以上的煩惱,Memori 說不定能解決你的問題。
Memori 是最近我和朋友合作的一個產品, 是一個能讓大家很輕鬆的上傳和即時瀏覽分享照片的服務。
19

Memori 可以經由簡單的介面,幫我們把照片上傳到 Google Drive,並且提供瀏覽的網址,就能很即時的分享、瀏覽朋友們拍的照片。
如果你辦活動,像是婚禮、聚餐,就可以把網頁投影到大螢幕上看看大家在現場拍了什麼照片,甚至用手機看也是可以的。
歡迎大家掃描左邊的 QR Code 上傳今天的活動照,也歡迎大家掃描右邊的 QR Code 看看大家上傳了什麼精彩的照片。
如果大家對這個服務有興趣歡迎找我玩玩看。
來玩玩看吧
20

在實作 Memori 的過程中,我是用前面提到的機制來檢視我們的效能問題的。
當瀏覽照片時,會經歷一段稍長時間的 loading,這麼長的等待時間,是什麼原因呢?
21
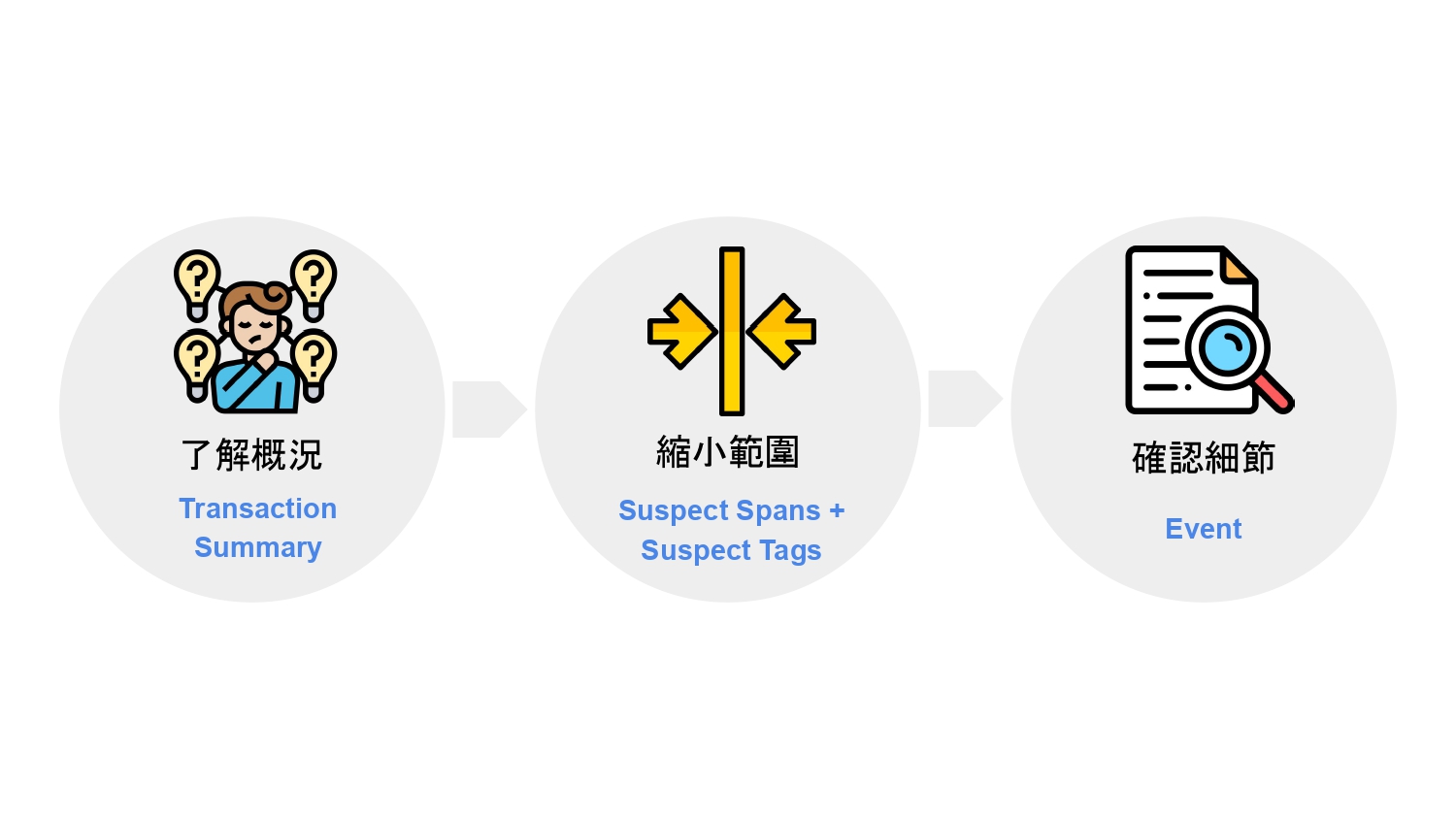
為了要解決載入時間過長的問題,我們需要更多資訊來確認問題所在,並在之後做驗證,看看問題有沒有被解決。
關於這個 case,我們接下來會做三件事:針對這個問題,了解概況、縮小範圍、確認細節,這樣才能針對問題找到解法,並在之後做驗證。
22
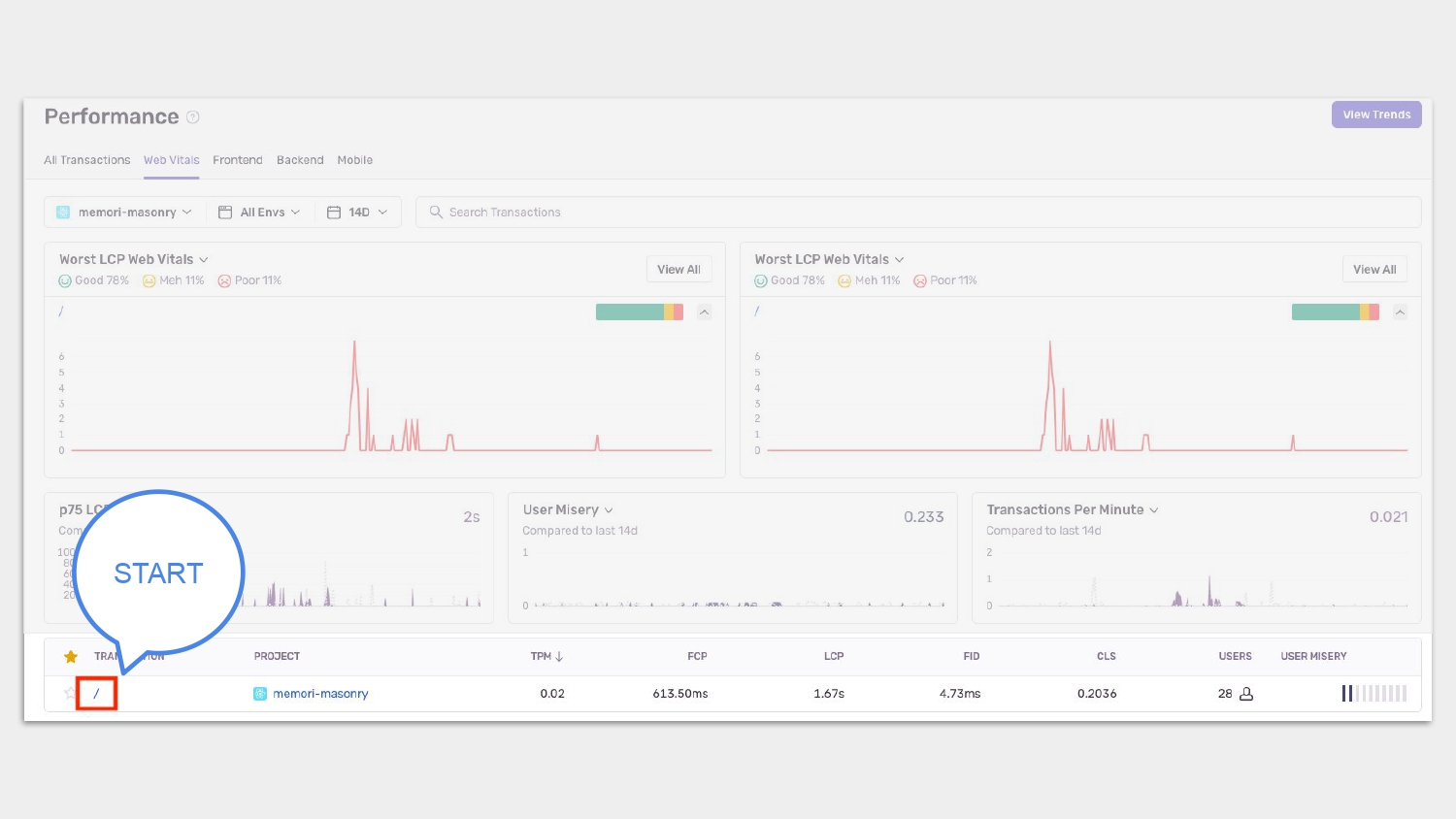
我在 Memori 裡面埋了 Sentry 的 JavaScript SDK,藉由 SDK 幫我們蒐集使用者的操作資訊。
既然是真實的使用者在操作時遇到了問題,就從 Sentry 這個實地工具來追追看是什麼問題。
首先我們點入 Sentry 的 Performance 頁籤,然後點我們要追查的 transaction,進入 Transaction Summary,先從 Summary 來了解概況。
順道一提,在追 SDK 的原始碼時,會看到是利用前面提到的 PerformanceObserver 來實作,取得 web vitals 的資訊的。
23
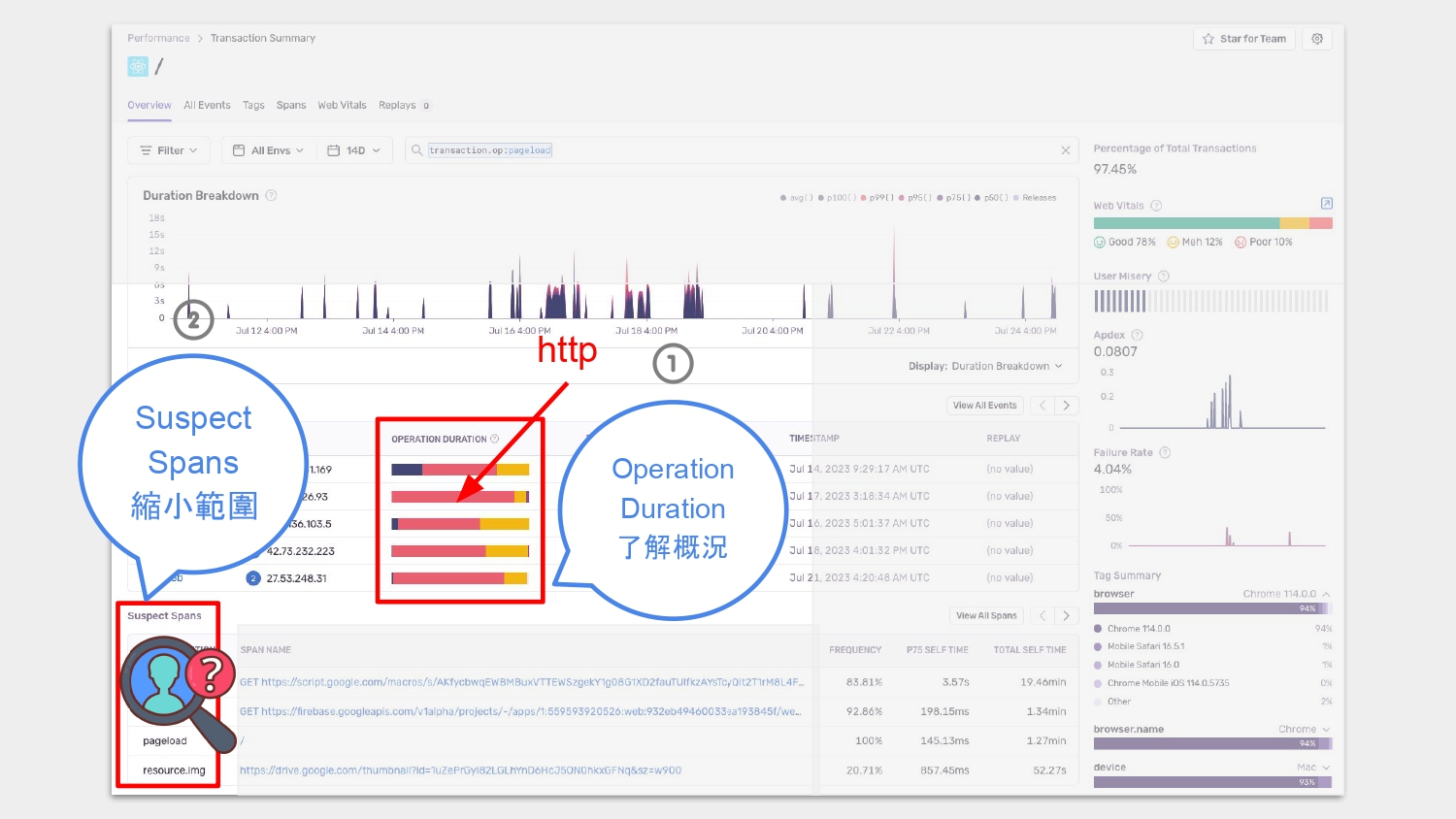
在 Transaction Summary 的 Operation Duration 能看到這個 transaction 全貌,讓我們對整個網頁載入圖檔的流程有個大概的了解。
說到確認問題所在,如果要我們在茫茫大海中找出問題在哪裡,就實在太花時間了。
Sentry 提供一個 span 的列表,它會挑出在指定時間內最有可能發生問題的 span,像是花費最多時間、FCP 最大的 span,這些最有可能發生問題的 span 稱為 suspect spans,在畫面的左下角的紅框,suspect spans 能有效地讓我們關注在最有可能發生問題的地方上,讓我們可以先點進去這些 suspect spans 做確認,有效縮小追查的範圍,減少追查問題的時間。
24
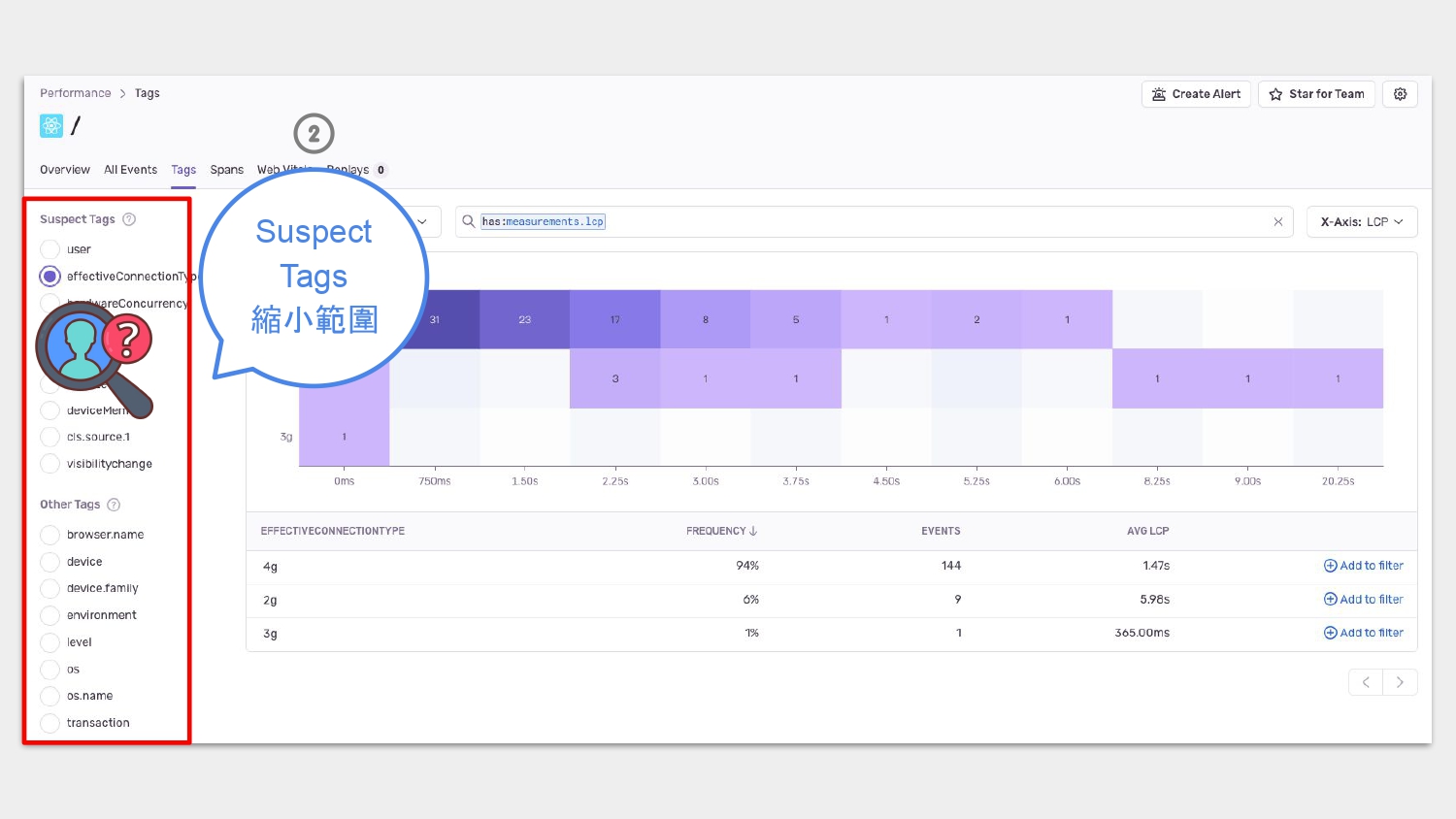
除了利用 suspect spans 縮小追查問題的範圍之外,還可以搭配 suspect tags,suspect tags 是 Sentry 用 heat map 來表示在發生問題時還有哪些常見的特性特徵,像是從這張圖可以看到,Memori 的大多數使用者是用 4G 網路、Chrome 瀏覽器。
經由這些特徵,我們在找問題時,就能更聚焦,順便做更多優化。
原來我們的使用者多數是用 4G 網路,那我們就在偵測到使用者用手機網路時,就用較差的圖檔解析度來呈現,這樣就能減少圖片載入的負擔;反之,遇到網路狀況較好就用解析度較高的圖擋。遇到 Chrome 瀏覽器就用 webp 的圖檔格式,如果不支援較好的圖檔壓縮格式就退化成 png。
我們只要多做一些額外的處理,就能讓產品使用起來更順暢,何樂而不為呢。
25
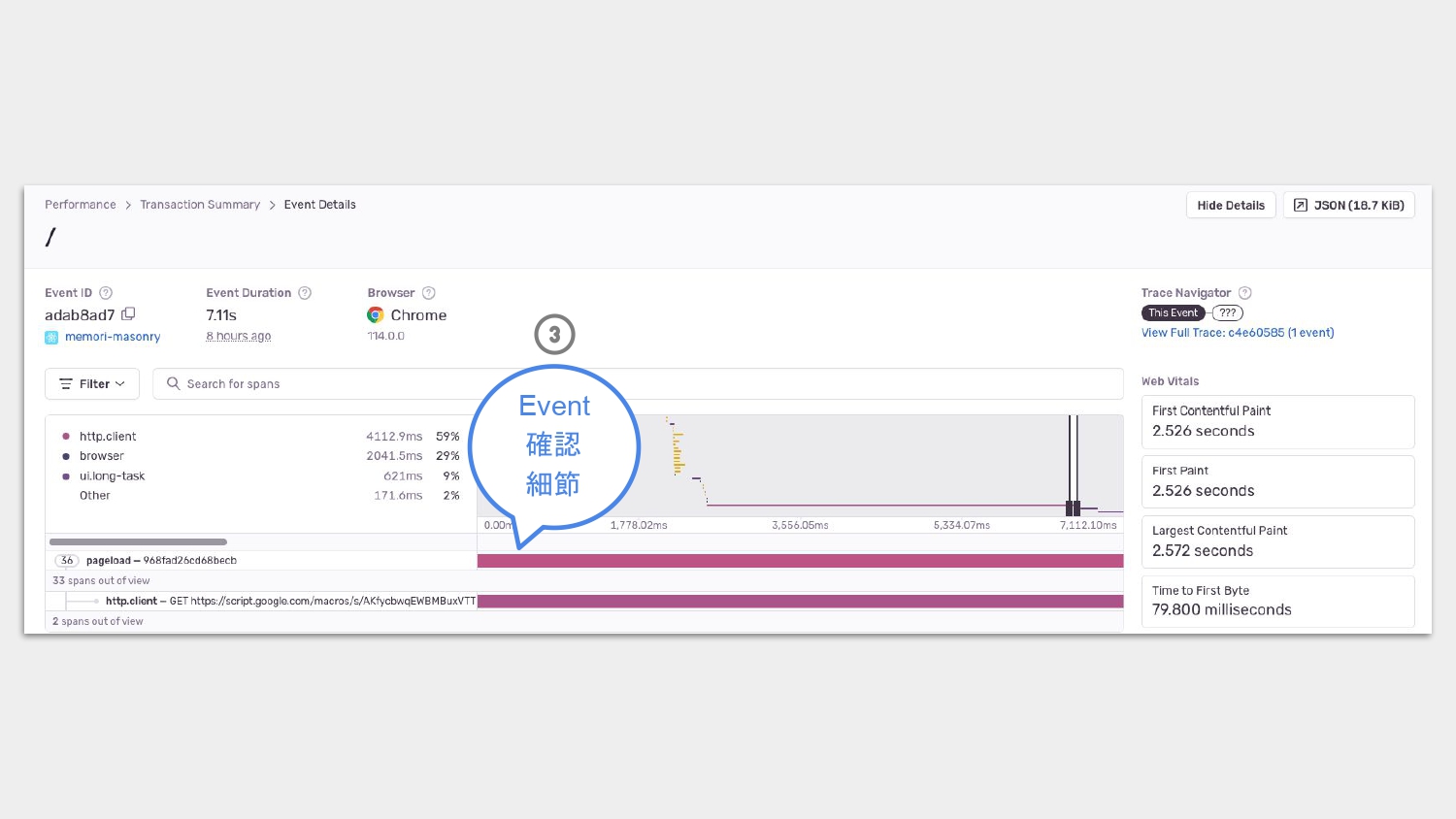
再任意點進一個 Event 來看細節,原來是等待 API 回應花太多時間了。
解法是設法讓 API 回快一點,或是預先打 API 等,有很多方法可以做改善。
從上面的例子呢,我們利用 Sentry 獲得更多資訊,來確認問題所在。
26

除了解決已知問題,前面提到,我們希望這個解法能有點預知能力,也就是希望在問題還沒發生之前,就告訴我們哪裡可能會出問題,這樣就能幫我們找出潛在效能問題。
那麼,我們怎麼利用 Sentry 找出潛在效能問題呢?畢竟,我們不希望是在問題發生後才解決問題,這樣反應真的太慢了,客戶可能都跑光光了。順道一提,如果大家有用過 Evernote,應該就會有類似的感概。
27

前面提到如何利用 Sentry 來解決我們的問題,第一個是 case 遇到確切的問題了,而我們需要更多資訊來協助判斷問題所在,並在之後來驗證問題是否已被解決;第二個 case 類似 routine 工作,目的是希望能預先找出潛在問題來做 enhance。
現在我們要來聊第二個狀況,接下來會從 User Misery 和 Threshold 加上 Alert 兩個方向來著手。
28
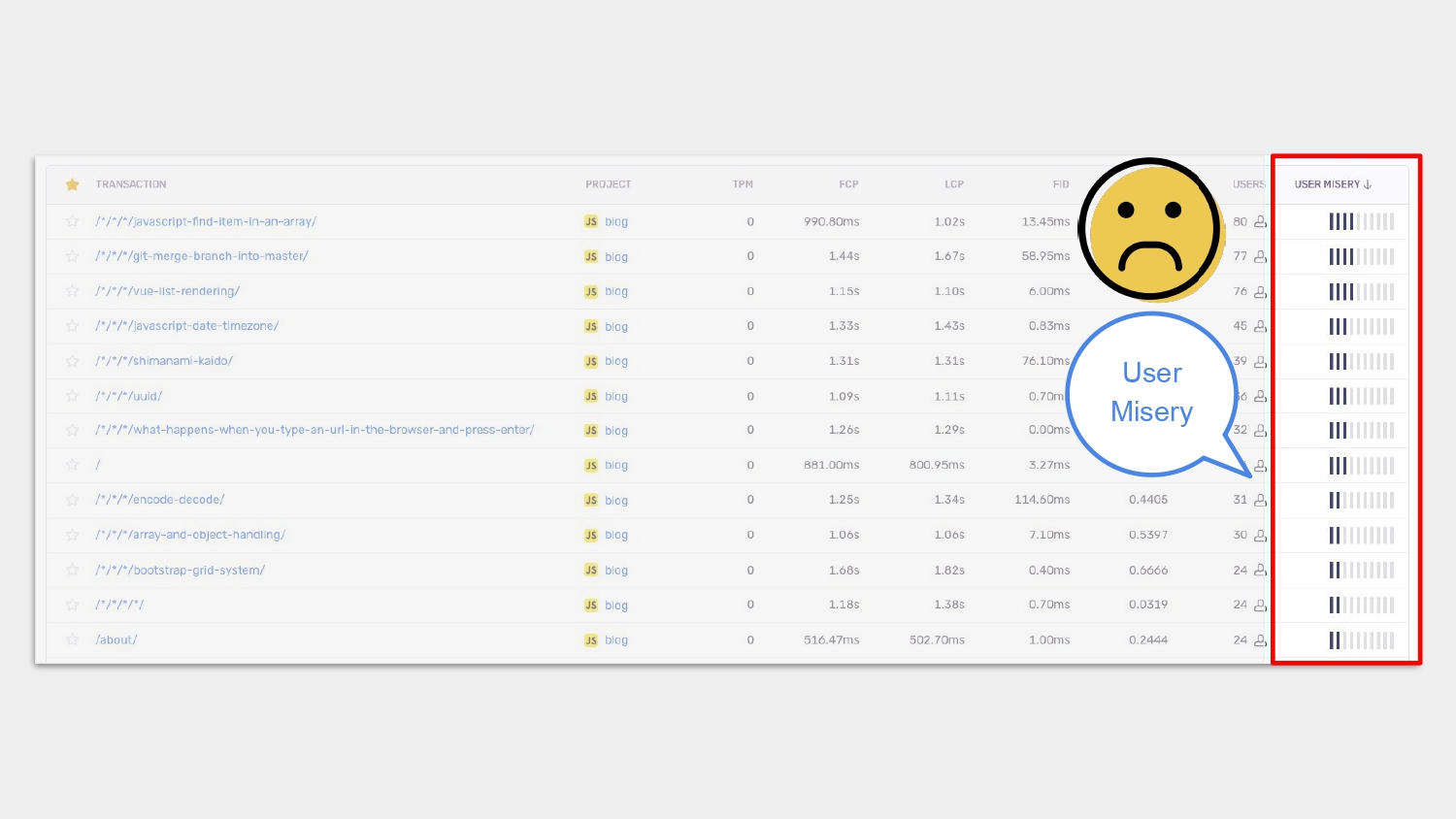
除了先前提到設定 threshold,像是利用前面提到的 LCP 等 metrix 來當成我們預測潛在問題的幫手之外,Sentry 還提供一個很神奇的東西,叫做 User Misery。User Misery 是用來計算使用者的痛苦程度,分數介於 0 - 1 之間,愈低愈好,計算方式可參考官網。
怎麼利用 User Misery 來幫我們找出潛在的效能問題呢?
第一步,在 transaction 列表中,利用 USER_MISERY 欄位幫 transaction 做排序,在排序後會得到使用者體驗最差、影響人數最多的網頁,那我們就優先處理這個網頁的問題。
第二步,點此網頁的網址進入 Transaction Summary ,再點進去任一個 event 到 Event Details 查看更多細節,經由觀察細節我們就可以知道可能是什麼問題。
29
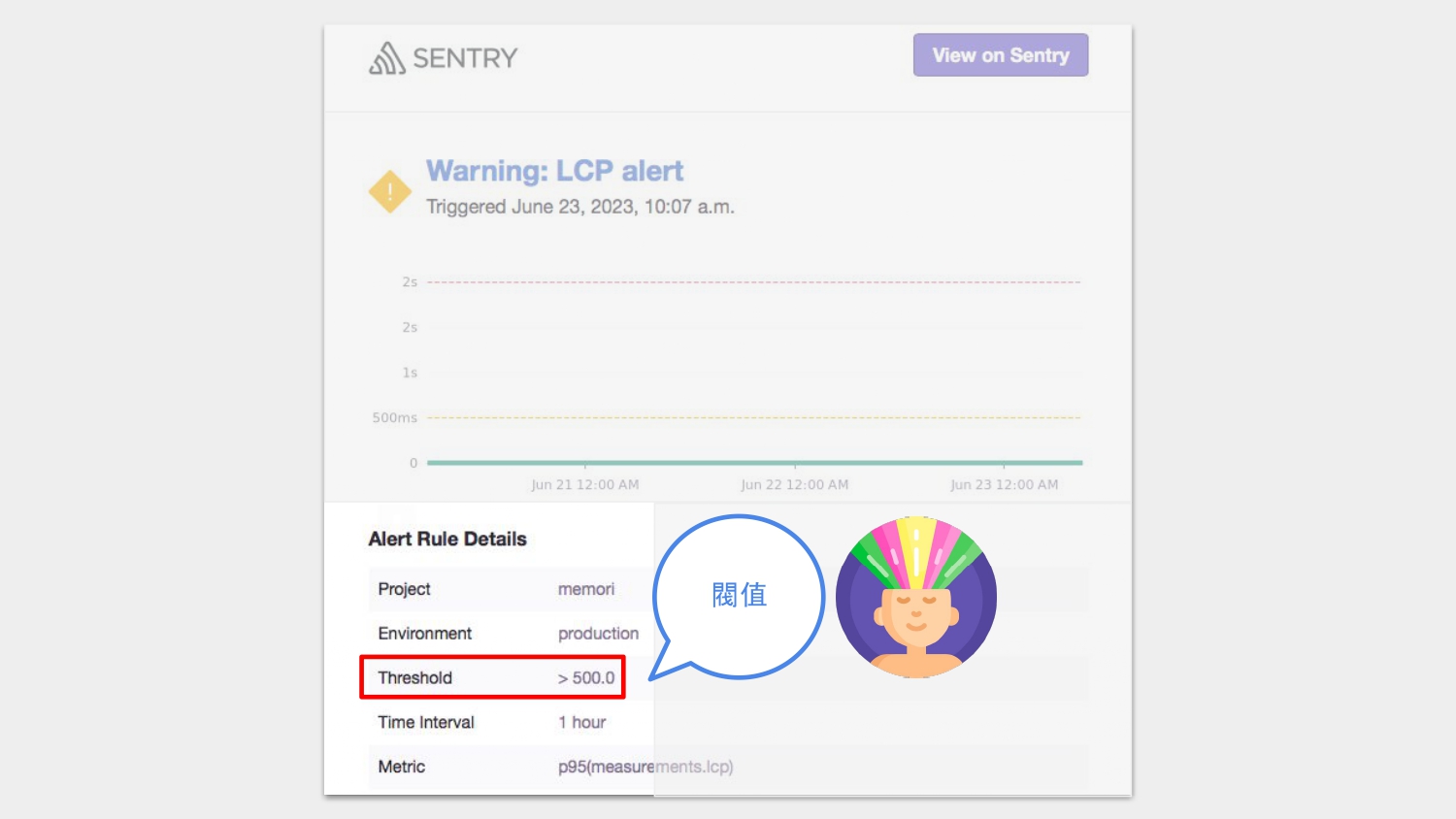
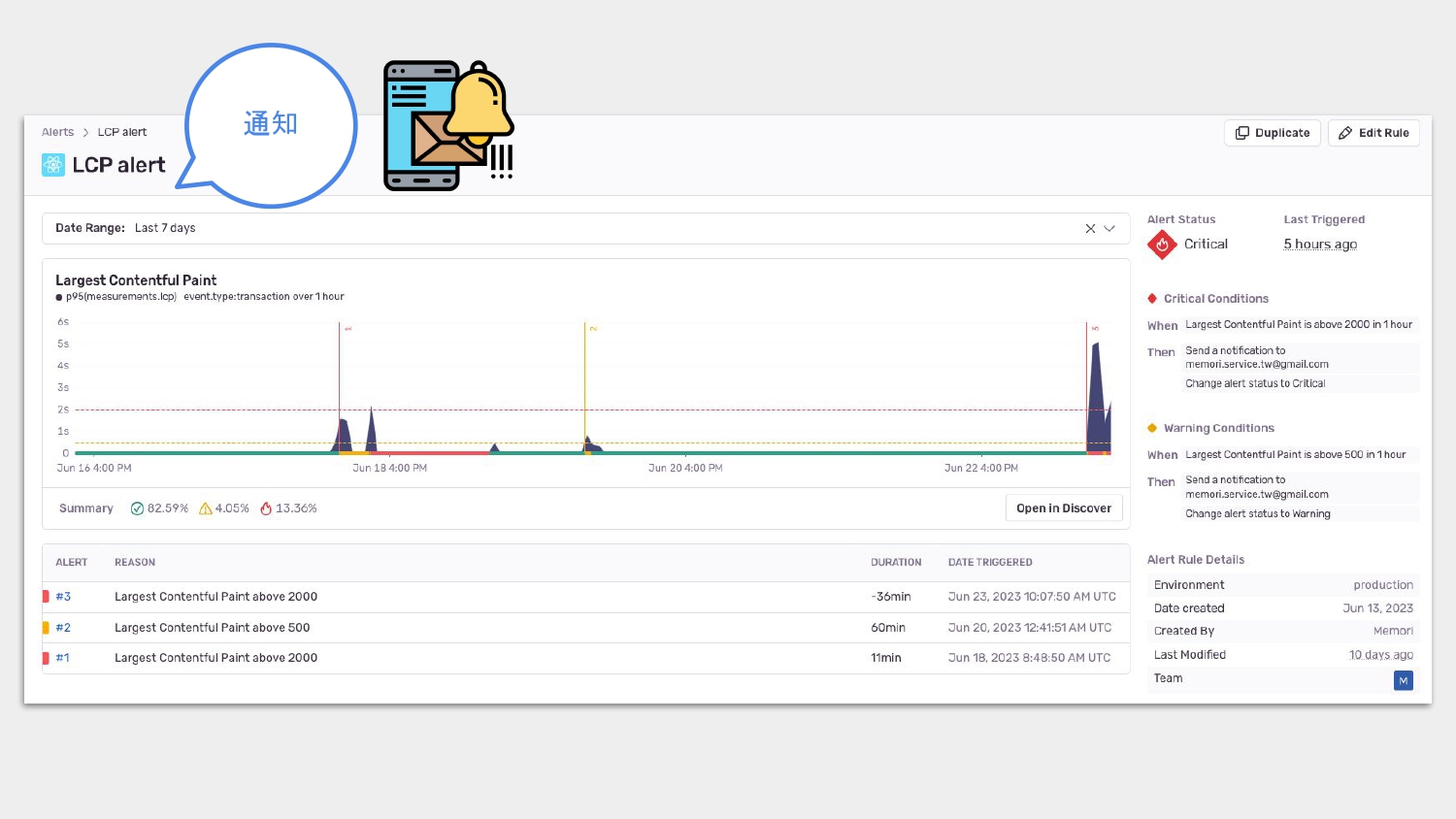
Sentry 除了能幫開發者追蹤與記錄問題外,更重要的是,它提供 alert 功能,能提醒開發者有異常狀況,趕快來處理吧!
這張圖是我個人的設定,Sentry 會在某個一小時內,若第 95 個百分位的使用者的 LCP 超過 500ms 就必須寄信通知。
如前面提到的,這樣設定的條件是比較嚴格,也因為這樣嚴苛的設定,我就會更謹慎地看待有沒有發生問題的可能性,及早處理,不過這個還是看產品性質,以及要跟團隊討論的。
很遺憾的是 Sentry 的通知功能是要付錢的,除了 Sentry 我們也可以改用 New Relic,它很佛心提供免費的通知功能,也能和很多東西做整合。
和 Sentry 定位不同的是,New Relic 比較像是 APM (application performance monitoring),它還提供來自不同 region 存取網站的選項,如果我想知道從美國、日本連過來是怎樣的速度、操作 UI 有怎樣的狀況,都可以加以模擬測試。
30
收到通知信後,點信件上的 View in Sentry 按鈕,即可進入 Sentry 的 Alert 頁面查看更多資訊。
關於通知,我們可以替換成自身專案適用的工具,或是調整適合的通知頻率。
31
剛剛提到的都是我們怎麼查問題,現在我們要來將模擬使用者操作的流程自動化,定期幫我們跑,或是在特定狀況下觸發幫我們跑,像是提交 PR 時。
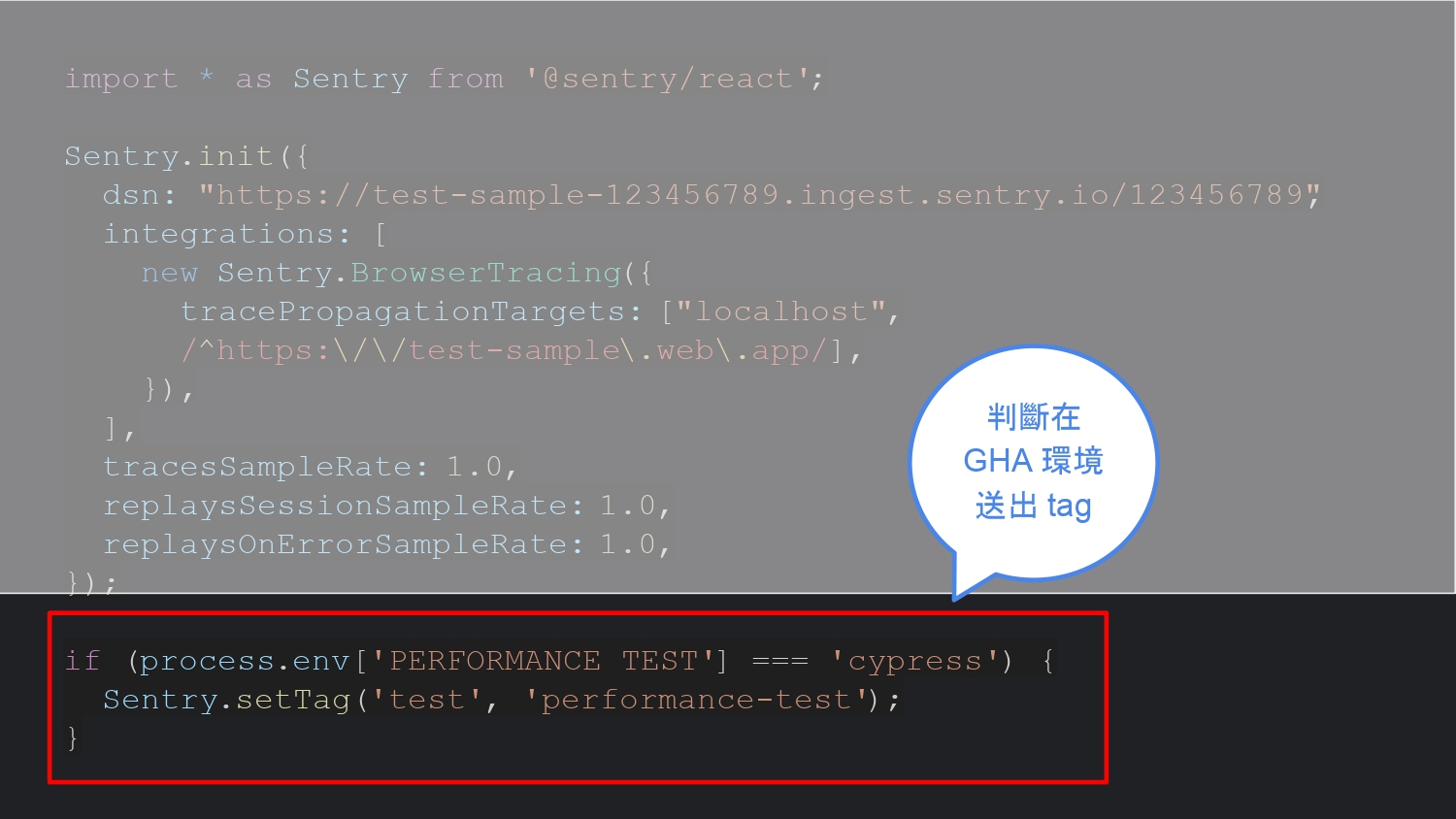
首先安裝 Sentry,由於在這裡是用 react 建立專案,因此是安裝 @sentry/react,Sentry 有支援其他前後端各種語言,選擇適當的安裝說明即可看到相關的範例程式碼。
為了要讓瀏覽時送出效能測試資料,因此在程式碼裡面,在初始化 Sentry 後,要加上判斷是否在 CI 在這裡是 GHA 環境來送出特定 tag,這樣之後在 Sentry 的 console 上才能順利用這個 tag 撈到資料。
import * as Sentry from '@sentry/react';
Sentry.init({
dsn: "https://test-sample-123456789.ingest.sentry.io/123456789",
integrations: [
new Sentry.BrowserTracing({
tracePropagationTargets: ["localhost",
/^https:\/\/test-sample\.web\.app/],
}),
],
tracesSampleRate: 1.0,
replaysSessionSampleRate: 1.0,
replaysOnErrorSampleRate: 1.0,
});
if (process.env['PERFORMANCE_TEST'] === 'cypress') {
Sentry.setTag('test', 'performance-test');
}
最後,檢視在 package.json 是否有 Cypress 的測試 script,記得設定檔要設定正確,然後就下指令來跑測試。
32
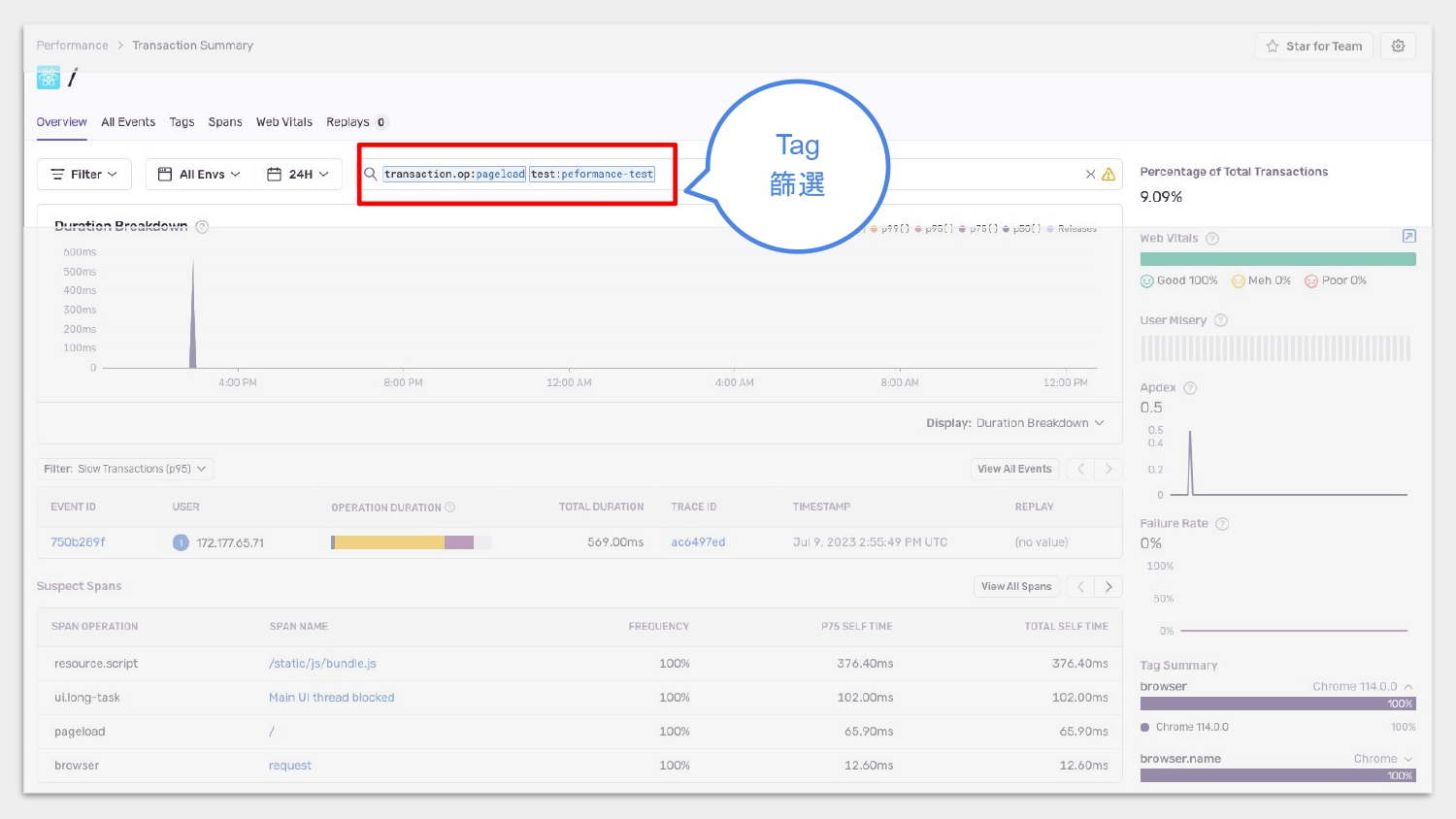
跑完測試後,稍等一下下 Sentry 的上傳和分析,即可看到測試結果。
在 Sentry 的 console 上,利用 tag 篩選剛剛特別為測試環境加上的 tag test:peformance-test 查看測試結果。
由於先前設定了通知,所以若測試結果高於預期,就會通知相關人等來做改善。
33
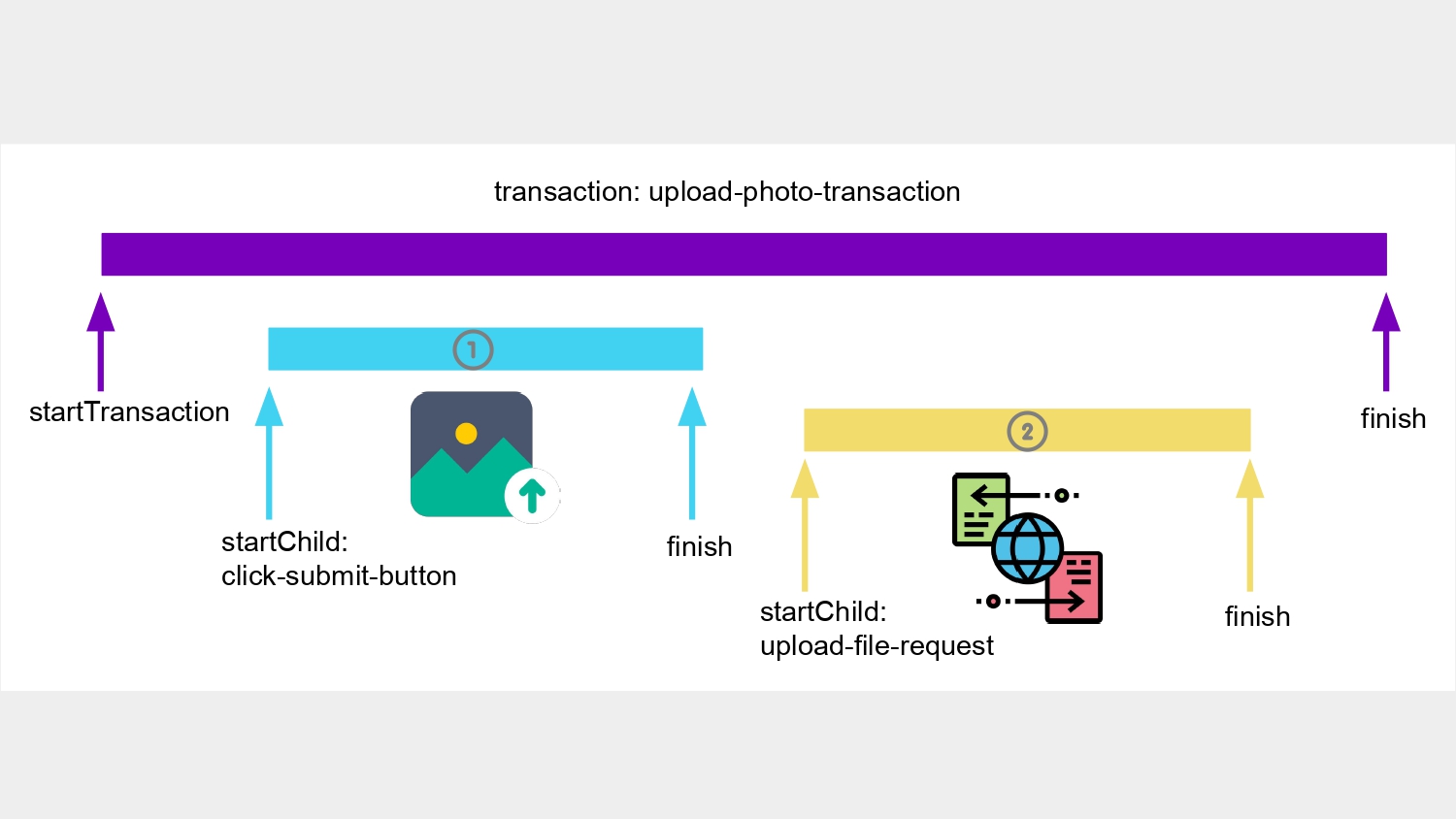
前面提到,我們想要優化 rendering performance,在實地測試工具中,像是 Sentry,我們可能沒有辦法直接計算畫面更新頻率是否達到 60fps,但我們可以追蹤操作時間是否過長來做改善,而 Sentry 提供的客製化測試流程,能幫我們達成這個目標。
舉例來說,圖片上傳。
我們可以設定追蹤客製化的 transaction,並在一個 transaction 裡面切分多個 span 來分段記錄細節,也就是在設定客製化的 transaction 上,用 startTransaction 開始,並用 finish 結尾,它們兩者之間的部份即為追蹤範圍。在這段範圍內,再用 startChild 與 finish 切分成多個追蹤區段。
34
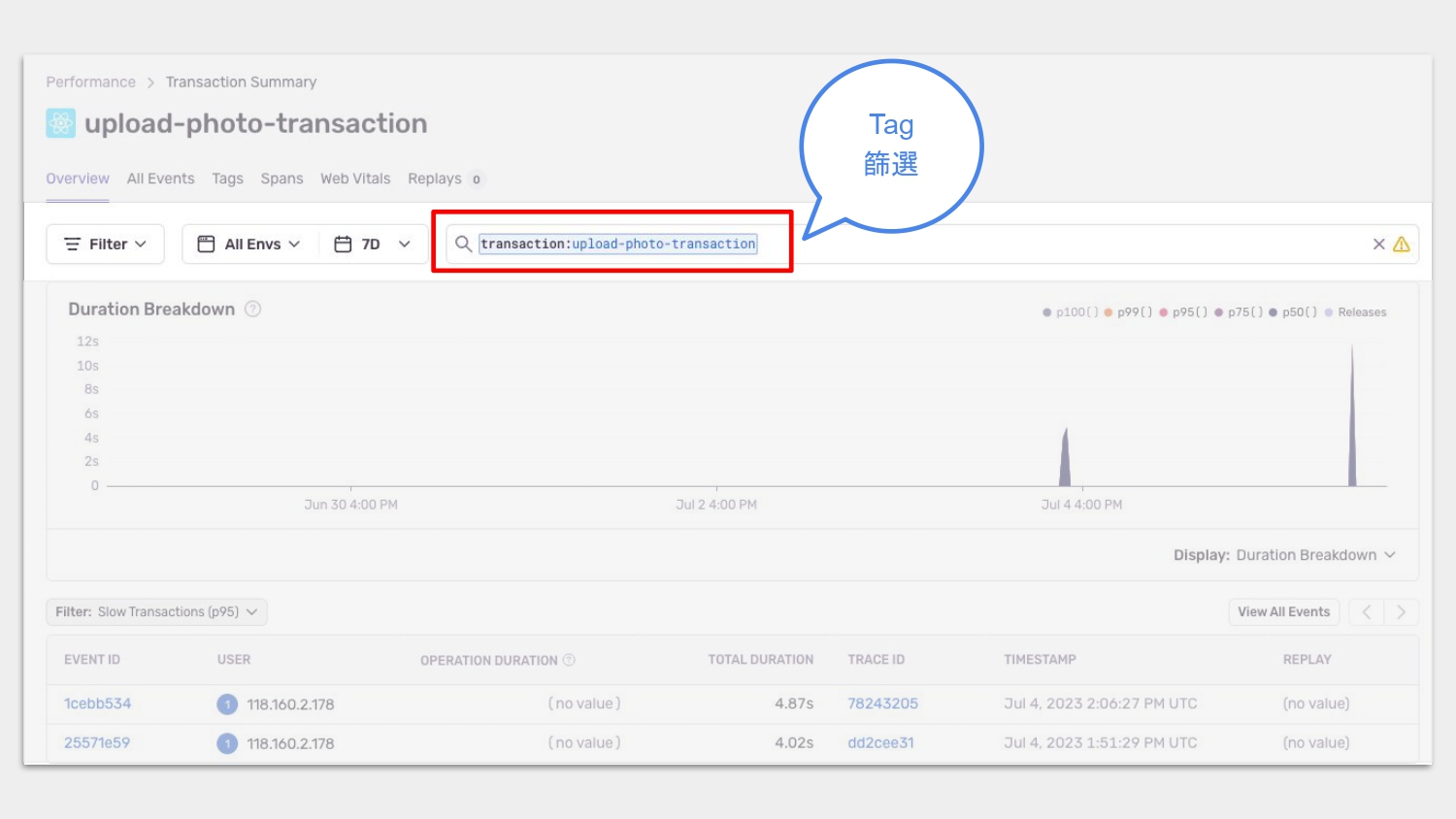
完成操作後,到 Sentry 的 console 上,利用 tag 篩選資料,就會看到 Sentry 幫我們找出在所選的這段時間內,在這個 tag 所標記的操作流程之下,所有發生過的 event。
像是在這裡,我們想知道上傳圖檔花了多久時間,就可以用標記的 tag upload-photo-tansaction 來撈出時間範圍內的所有 event,就可以根據這些 event 觀察他們的狀況。
35
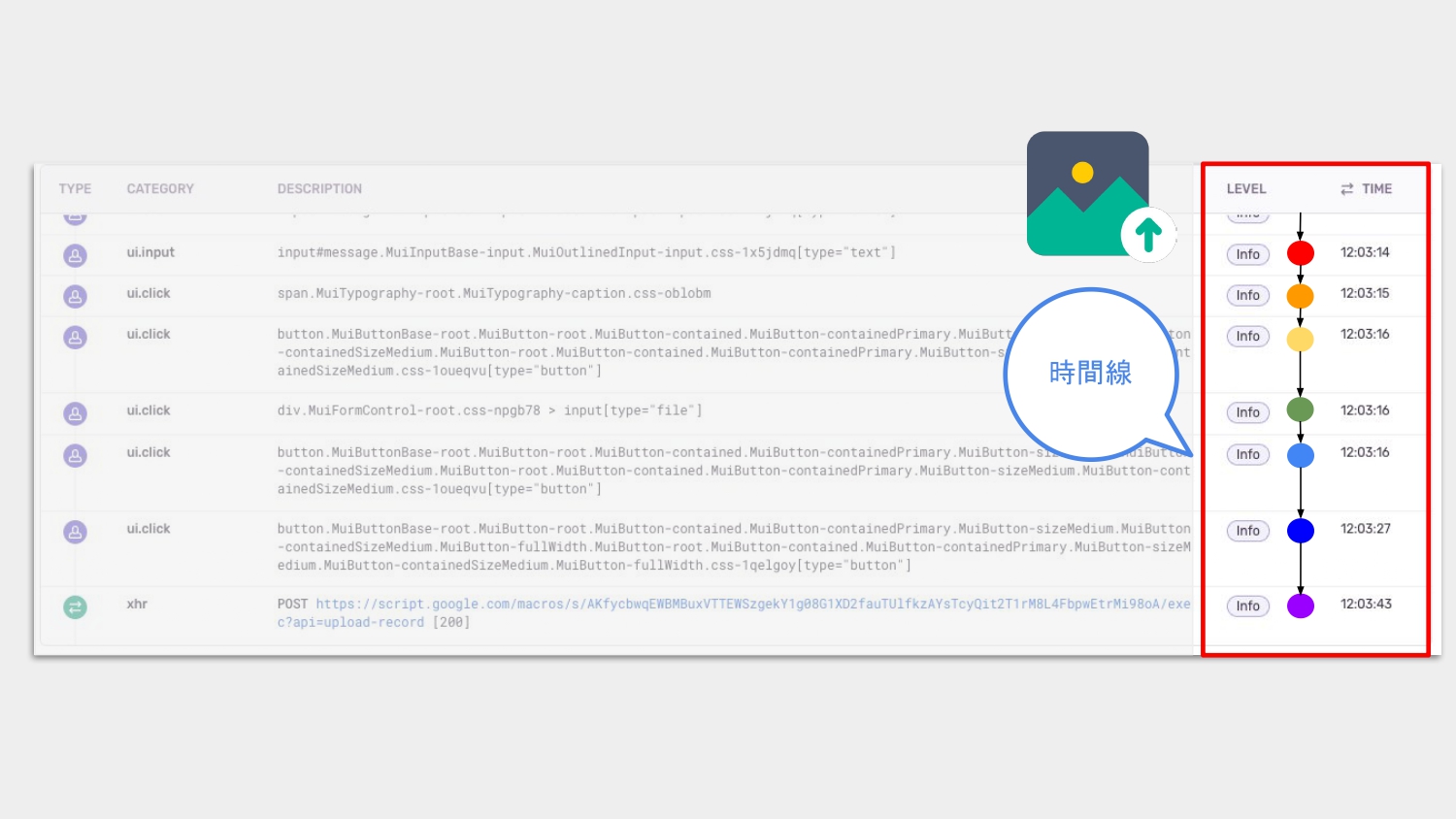
再次說明,產生 rendering performance 最常見原因之一是 long task,long task 會 block UI 的顯示,導致操作 UI 時可能會有卡卡的狀況。
針對這個問題,我們想知道是否有 long task 的狀況,就可以藉由觀察時間線 timeline、計算每一段過程的時間來得知是否有這個問題,右邊紅框框出了每一個步驟的時間點。
舉例來說,點按鈕的時間點是橘色點到藍色點,相差約 10ms,藍色點到綠色點是點按鈕之後發出網路請求,約花費 16ms,反應時間都小於可能會造成 long task 的 50ms,那麼就可以猜測使用者應該使用得很順暢的了。
我們來做了簡單結論,在選擇要用哪一種資料採集的方式上,如果想要分析 loading performance,Sentry 提供 web vitals 的功能已經很足夠了;但若想改善 rendering performance 或特定 UI 的行為,使用 Sentry 的自訂追蹤功能會是很好的解法。
36
最後,我們來將模擬使用者操作的流程自動化。
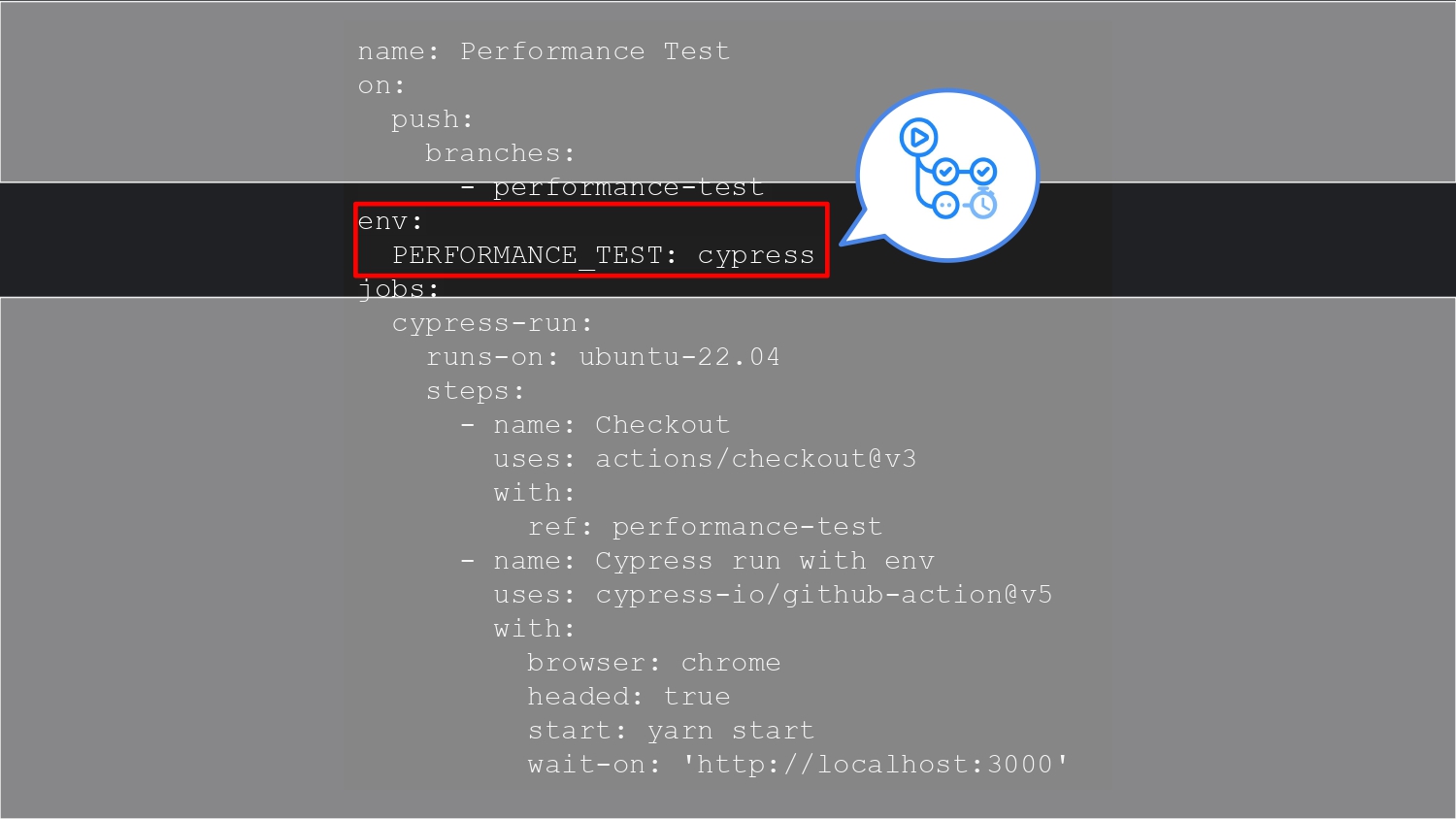
也就是說,希望這個流程能在 CI/CD (在這裡是 GHA) 的環境下來跑。這是因為在做效能測試時,我們會希望能在統一的環境和機器規格下比較,也希望能定期或針對每個版本來做比較。
為了要能在送資料給 Sentry 時能夠辨識哪些是我們特別在 CI/CD 之下測試的,我們必須要在 GitHub 先設定環境變數,這是為了當資料上傳到 Sentry 上時,要能經由特定的 tag 撈出測試資料。
name: Performance Test
on:
push:
branches:
- performance-test
env:
PERFORMANCE_TEST: cypress
jobs:
cypress-run:
runs-on: ubuntu-22.04
steps:
- name: Checkout
uses: actions/checkout@v3
with:
ref: performance-test
- name: Cypress run with env
uses: cypress-io/github-action@v5
with:
browser: chrome
headed: true
start: yarn start
wait-on: 'http://localhost:3000'
完成以上步驟,我們就可以做自動化的效能測試了!
37
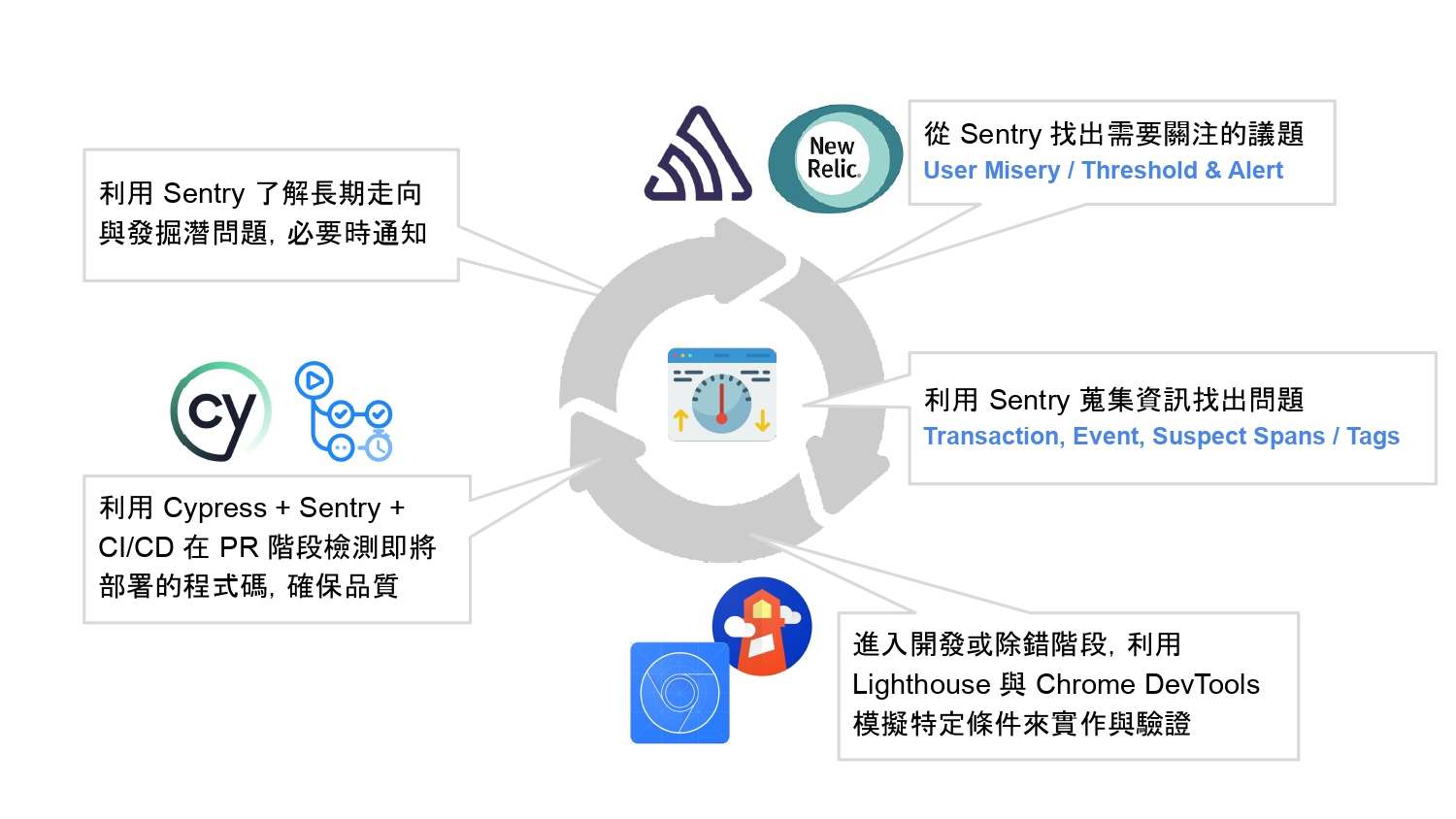
前面講了好多好多,那就在最後,來總結一下工作流程。
- 第一步:從 Sentry 找出需要關注的議題,像是待解的問題,或是由 User Misery 或我們自己定義的 threshold 篩選出來可能要關注的問題。
- 第二步:根據這個問題或狀況,利用 Sentry 的資訊找出問題所在。
- 第三步:進入開發或除錯階段,可以使用工具 Lighthouse 與 Chrome DevTools 來幫我們模擬特定的條件重現與改善問題。通常這個過程需要來回多次。
- 第四步:利用 Cypress + Sentry + CI 在 PR 階段檢測即將部署的程式碼,以確保產品品質。
- 第五步:持續使用 Sentry 蒐集 production 上的資料,驗證在真實環境中問題是否解決,並觀察使用者實際操作的狀況而發掘是否有潛在的效能問題。
38
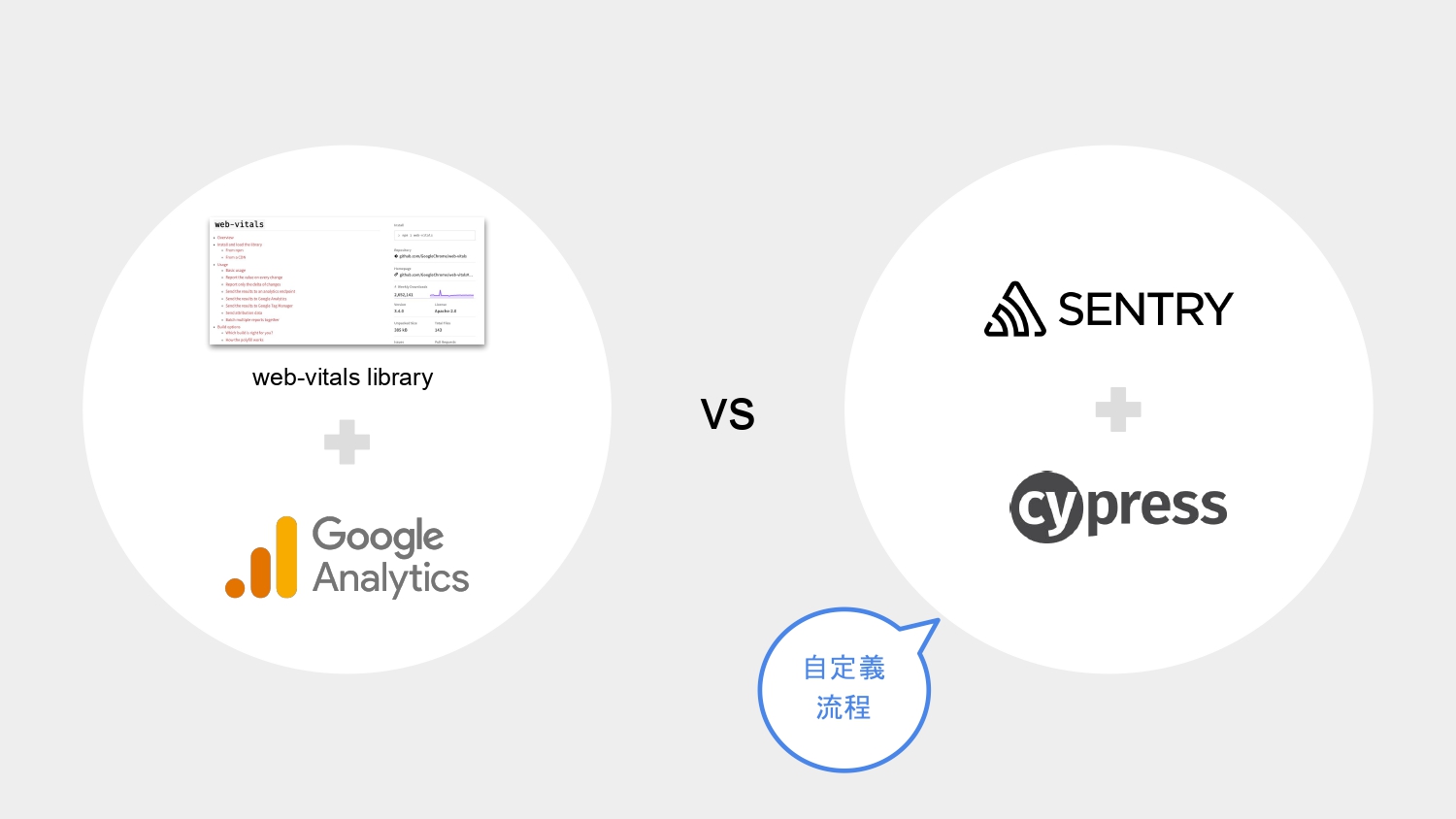
這邊要提一件事情… 在做自動化測試前端效能時,可能會考慮的解法有這兩種,我們來比較一下。
第一個解法是 (1) Lighthouse CI Action 或 web-vitals library 選一個,再加上把資料丟到某個地方做儲存和顯示用的 dashboard,像是 GA;另一個解法是 (2) 利用 Cypress + Sentry 來取得相關資訊並做呈現。
若是在評估要用哪一個當解法,我的想法是,(1) 與 (2) 都能做到網頁載入的效能檢測與提供 web vitals 資訊,唯一不同處在於 (2) 利用 Cypress + Sentry 可提供自行定義測試流程,以及除了 web vitals 之外更多資訊。如果想追查 render performance 或是 long task 的問題, 利用 Cypress + Sentry 是一個很好的解法。
就看團隊和專案需求,來做出適合的選擇吧!
39
我做了一個簡單的 repo 來 demo 如何建構這個效能測試的機制。 有興趣的人可以玩玩看。
40
特別感謝合作團隊 Memori、Sean Chou、Yvonne Huang 和 Shelly Chen。
41

歡迎大家來上傳和瀏覽活動照片!歡迎追蹤 Memori 的 IG。 本次分享會有逐字稿。 以上是我的分享,感謝大家!
WebConf 2023
感謝今年有機會再度跟技術社群分享,祝大家也祝自己都能玩得開心!



感謝泰銘 Timing JL 在會前幫忙順稿和給予建議,也謝謝大家的支持和鼓勵。附上泰銘的點評 - 【心得】2023 WebConf 為自己留下記錄的參與心得
")



