利用 Sentry 進行效能監控
29 Jun 2023![]()
前言
身為開發者的我們應該常遇到這種情況…
客戶或 QA 敲了一個 bug,收到 tacker 後幾乎毫無頭緒、不知如何開始,如果能給個線索就太好了?通常會用以下的方式拿到一點點提示…
- 方法 1:請事主錄製操作流程,或是面對面操作一次,設法 reproduce,還原問題的來龍去脈,了解事情是怎麼發生的。
- 方法 2:從 tracker 附上的 error log 與 trace 程式碼後的結果,猜測問題發生的原因與流程。
關於方法 1,若是偶發狀況,就不太容易用這種方法重現問題;而方法 2 的確是比較常用的方法,但前端的程式碼要怎麼埋 log 送回自己家呢?送回來以後,要怎麼查詢和檢視呢?能不能在被人發現問題之前,一有問題就立刻自動通知開發者呢?最好還能幫忙預測潛在問題所在?
剛好最近在找個能進行效能監控的工具,在考量是否能有效記錄與追蹤特定指標和錯誤、整合、即時通知與 self-hosted 後,決定使用 Sentry 來協助團隊進行效能與錯誤的監控。
Sentry 是什麼?
Sentry 是一個以開發者為導向的錯誤追蹤和效能監控平台,目的是協助開發團隊提升產品品質和使用者體驗。以下是 Sentry 的主要功能和特點:
- 錯誤追蹤:Sentry 可以追蹤並記錄應用程式中的錯誤、例外情況和崩潰,提供詳細的錯誤報告和堆疊跟蹤,協助開發團隊定位和修復問題。
- 效能監控:Sentry 提供效能監控功能,追蹤應用程式的 response time、latency、web vitals 和 throughput 等指標,幫助辨識和解決效能問題,以提升系統效能。
- 即時通知:Sentry 提供即時通知機制,將錯誤和例外情況的通知發送給相關團隊成員,以快速回應和解決問題,減少停工時間。
- 整合和擴展性:Sentry 可與其他開發工具和服務進行整合,如原始碼管理系統、持續整合/持續部署 (CI/CD) 工具和通訊軟體等,同時提供豐富的 API 和 SDK,方便客製化更多功能。
- 支援多語言:Sentry 支援多種程式語言和框架,如 Python、JavaScript、Java、Ruby 和 PHP 等,使其適用於各種不同的應用程式。
點這裡看 Sentry 官方簡介影片。
總結來說,Sentry 的目標是讓開發團隊能夠迅速發現、解決問題,並持續改進軟體品質和用戶體驗。
如何利用 Sentry 解決問題?
在這裡分為兩個 case ~
- 第一個 case 是遇到確切的問題了,而我們需要更多資訊來協助判斷問題所在,並在之後做驗證問題已被解決。
- 第二個 case 類似 routine 工作,希望能預先找出潛在問題來做 enhance。
注意,在這裡主要是探討解決效能問題,怎麼解決 bug 就不在本文討論範圍之內了,但概念應該是相同的。
範例 1:畫面轉轉轉到讓人以為壞掉?
如下圖所示,畫面轉轉轉,慢到讓人以為壞掉?幸好等到最後還是有東西出來了。是什麼原因要等這麼久呢?

進入 Sentry 後,從 Performance 頁籤點該 transaction 進入 Transaction Summary 頁面,在 Transaction Summary 能看到這個 transaction 全貌,能有個大概的了解。
![]()
在 Transaction Summary 可看到這些 transaction 的狀況其實都大同小異,大多是 http 佔了大部分的時間,下方 Suspect Spans (翻譯:可疑跨度) 幫我們猜測是打 API 時回應資料的速度太慢導致 block UI 的呈現。
![]()
在追蹤問題時,我們若是將整個 transactions 的工作或操作 (稱為 span) 拿出來看,是很浪費時間的。Sentry 提供一個 span 的列表,挑出這段時間內可能有問題的 span,像是花費最多時間、FCP 最大的 span,這些最有可能發生問題的 span 就稱為 suspect spans,suspect spans 能有效地讓我們關注在最有可能發生問題的地方上,進而快速解決問題。
搭配 operations breakdown 和 suspect tags 會更好用,suspect tags 用 heat map 來告知在發生問題時有哪些特性是常見的,像是大多使用者可能是用 4G 網路、Chrome 瀏覽器等。
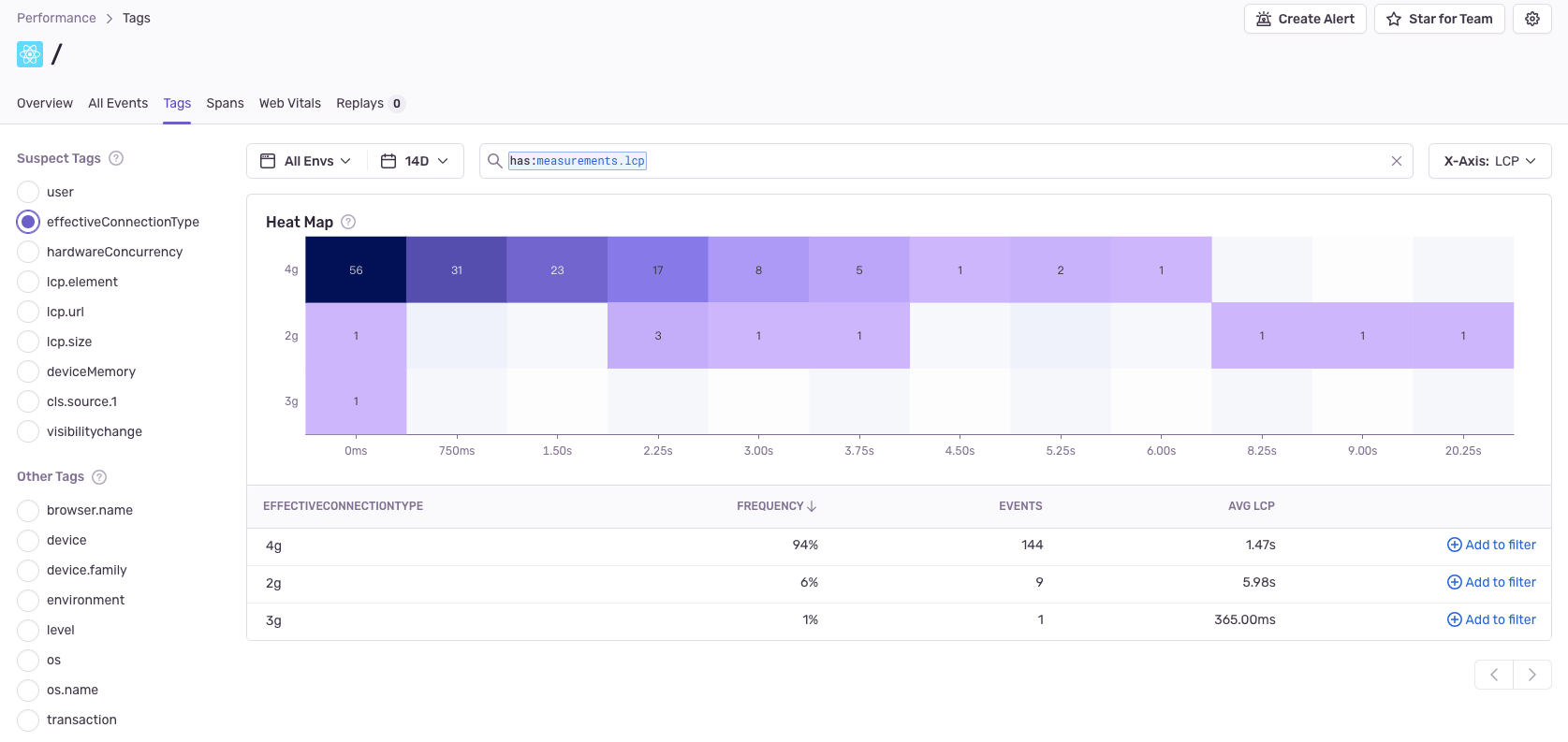
再任意點進一個 Event ID 來看細節,的確是這支 API 回應花太多時間了。
![]()
從這邊我們利用 Sentry 確定了問題所在,接著就是來思考怎麼解決,不外乎是設法讓 API 回快一點,或是預先打 API、做快取或是讓 UI 做一些遮掩騙騙使用者等。
範例 2:找出潛在問題
不用等問題出來再解決,我們也可以先來找出潛在問題,步驟如下。
第一步,利用 User Misery 來找出會影響最多使用者的地方著手。User Misery 是一個很奇妙的東西,它用來計算使用者的痛苦程度,分數介於 0 - 1 之間,愈低愈好,代表體驗到超過專案設定 threshold 四倍的 load time 的使用者比例。它根據開發者在系統設定的 custom threshold 而有所不同,計算方式可參考官網。
在 Performance 頁籤 filter 出多數使用者會花最長時間的 transaction,也就是點 USER_MISERY 欄位來做排序,作為優先處理的依據。在排序後發現是 /array-and-object-handling 這頁的使用者體驗最差、影響的人數也最多,所以優先處理。
![]()
第二步,點此 transaction 進入 Transaction Summary ,再點進去任一個 event 到 Event Details 查看更多細節。
在 Event Details 可知大多是 resouce 花費大多載入時間,解法有非必要在第一頻讓使用者看到畫面的 script 可用非同步載入、圖片優化 (減少體積、根據裝置決定載入哪一種格式或畫質的圖檔)等。
![]()
即時通知
Sentry 除了能幫開發者追蹤與記錄外,更重要的是能即時通知開發者問題發生了,來處理吧!若是真的等到使用者反應效能狀況不佳才做改善就太慢了;或是根據設定的條件來預先判斷是否可能有異常狀況。。
Sentry 提供 alert 功能,如下圖可設定不同條件來寄信通知。
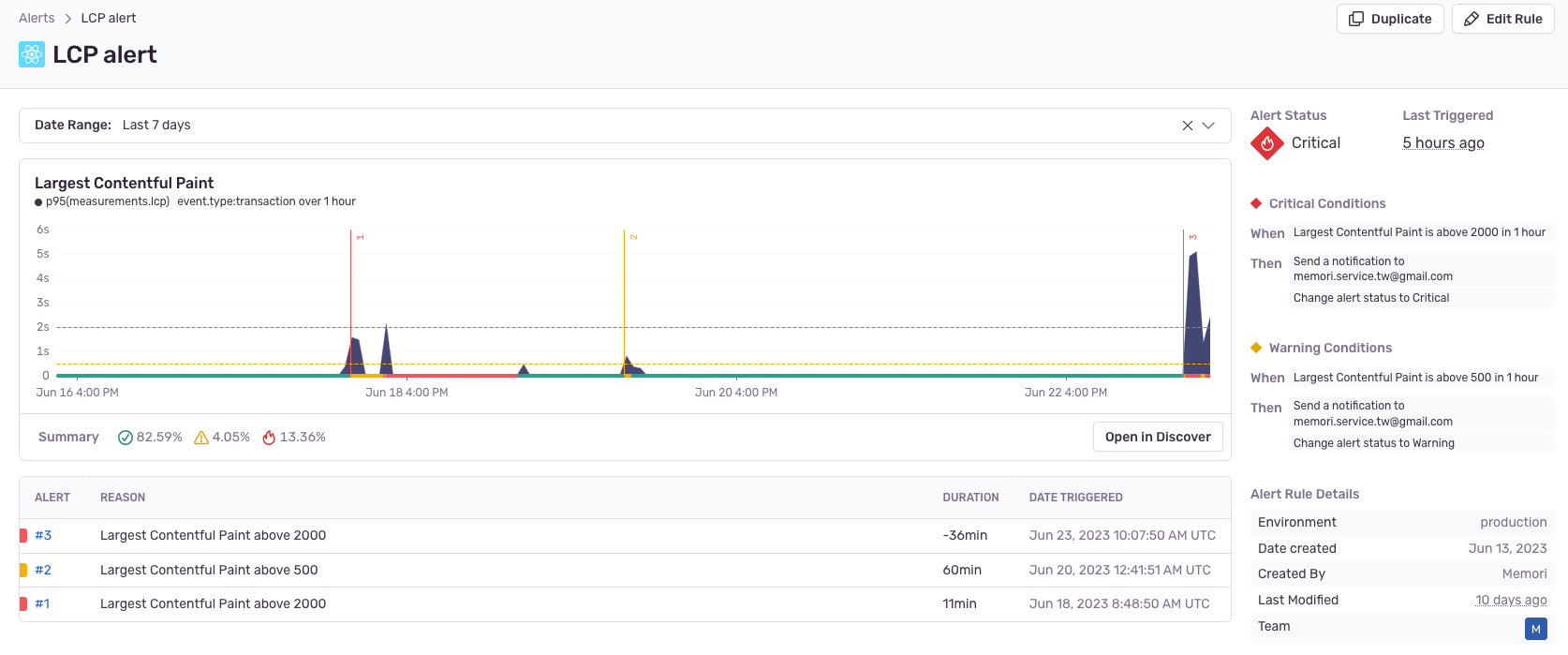
這是我個人的設定,Sentry 會在某個一小時內,若第 95 個百分位的使用者的 LCP 超過 500ms 就必須寄信通知。
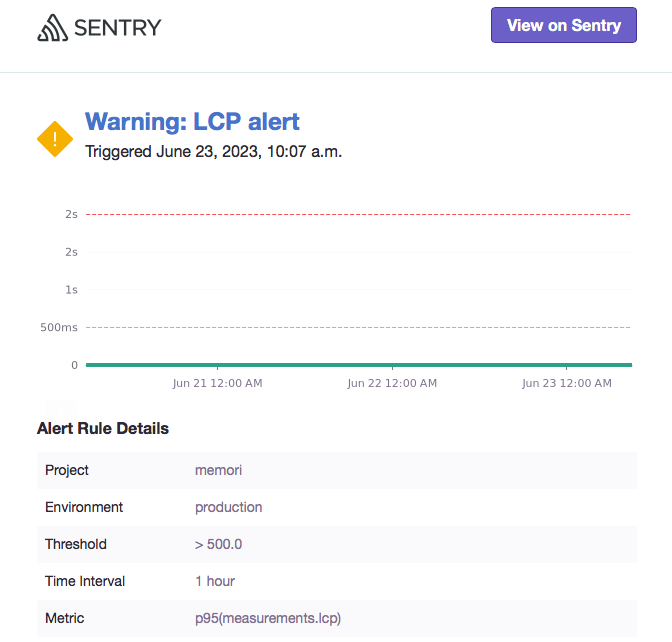
這樣設定的條件是比較嚴格的,照理來說 LCP < 2.5 秒即是良好,但現在大多使用者的網路和設備條件都很不錯,尤其在桌機 + WIFI 的狀況下更是如此,等待 0.5 秒應該是許多人耐心的極限了,因此在這裡設定若超過 0.5 秒還無法讓人看到個 loading icon 就必須來查查看是不是有什麼問題。
點信件上的 View in Sentry 按鈕進入 Sentry 的 Alert 頁面查看資訊。
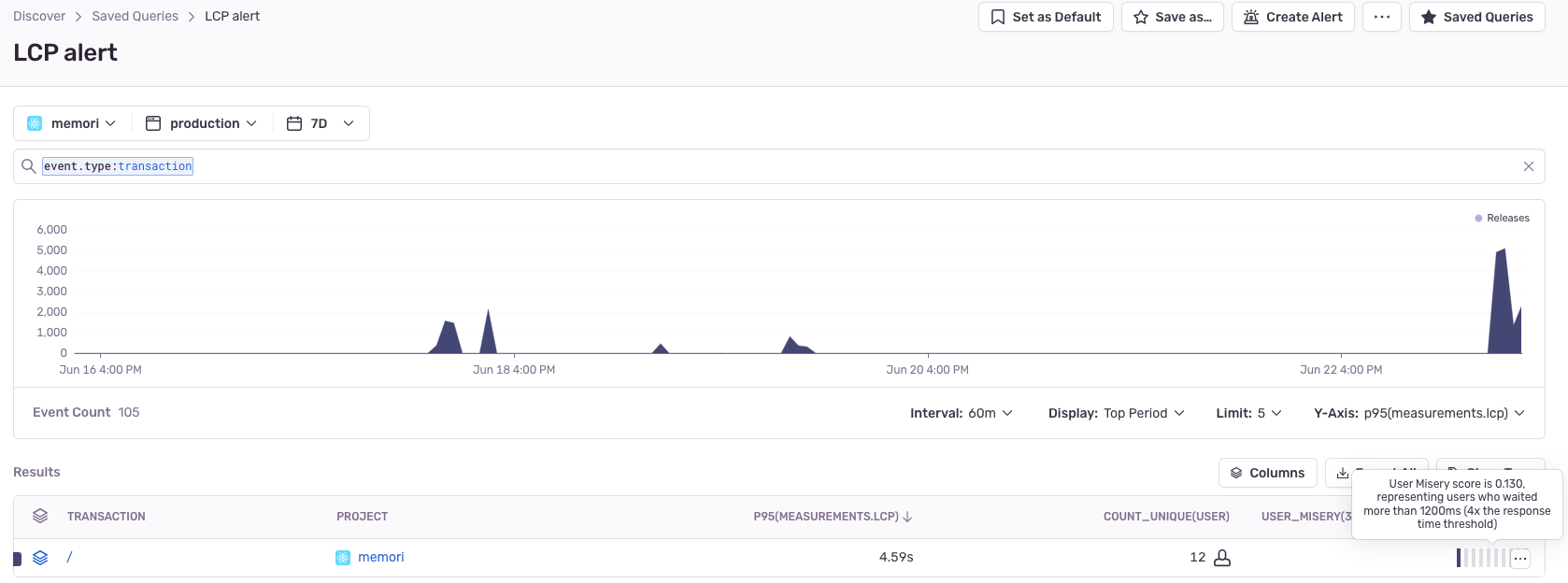
再從 Alert 點 Open in Discover 進 Transaction Summary 來看細節,原來是 http request 回應過慢,改善方式跟前面提到的剛好一樣,就是讓 API 回快一點,或是預先打 API、做快取或是讓 UI 做一些遮掩騙騙使用者等。

總結
在開發環境 (development) 使用 Lighthouse 與 Chrome DevTools,再搭配使用 Sentry 來追蹤和分析正式環境(production) 上的狀況,的確是很好的一套解法。
如果有收費考量或安全性疑慮可考慮 self-hosted 版本。



 MOPCON 2021 逐字稿")
")
