如何撰寫具彈性的測試程式 | 2024 WebConf Taiwan
27 Dec 2024「如何撰寫具彈性的測試程式」2024 WebConf Taiwan 講稿,歡迎搭配投影片一同閱讀。
1

大家好,我是 Summer,今天想跟大家分享的是「如何撰寫具彈性的測試程式」這個主題。
2

簡單自我介紹一下。
我是 Summer,目前主要是做前端開發,擅長測試、效能調校和 SEO。
大家可能比較知道的是我的部落格,「Summer。桑莫。夏天」,主要是前端技術的分享。
我寫過三本書,一本是「打造高速網站,從網站指標開始!全方位提升使用者體驗與流量的關鍵」,這是關於前端效能的書。
今年有出一本測試的書「前端測試指南:策略與實踐」,如果大家對於前端測試有興趣,歡迎找來看看。
第三本即將出版的,是這本測試的書的英文版。(備註:原本已出版英文版電子版@Leanpub;英文版紙本與電子書後來皆委託美國書商出版,預計 2025 年 2 月上市。)
下面是我的 Instagram、FB 和 Email,歡迎交流!
3

寫測試的目的是為了確保產品品質,大家的主力大多是放在開發,所以怎麼用最少的資源達到最好的保護效果是很值得探討的議題。
如果你跟我一樣,每天都非常忙碌像打仗一樣,那麼你應該對這個主題感到有興趣,因為這個分享的核心概念是如何省時省力。
接下來我們會從怎麼寫一個好維護的測試程式,進而談到怎麼拆分功能,最後來看如何針對專案來設計適合的測試架構。
4

具體來說,這次的分享想跟大家聊聊的是,如何撰寫具彈性的測試程式。
這個可以分兩個方面來說:
- 第一個是在寫測試程式上,怎麼寫出適應變更、有彈性的測試程式?
- 第二個是在設計測試架構上,怎樣才能做到花最少的成本,又能達到最好的保護效果?
5

首先,我們先來看「怎麼實作適應變更、有彈性的測試程式」。
6

我們在寫測試的時候,一定會遇到測試失敗的狀況,那麼測試為什麼會失敗呢?大概可以分成以下幾個原因:
- 第一,需求變更。需求變更、修改程式碼,相對應的測試就必須做調整,來因應變化。在調整之前,測試一定會失敗。
- 第二,程式的設計或實作不良,像是邏輯不通、有 bug,執行測試時就很容易找到問題而導致測試失敗。我們可以透過找出程式的問題,並且修正它,來解決這個問題。
- 第三,flaky test,就是不穩定的測試,例如:test case 彼此之間有相依,或是資源有相依,這根本上的原因是測試程式本身在設計或實作上有問題。我們可以透過隔絕依賴、確保測試執行前或後處於相同的狀態,來解決這個問題。
- 第四,就是今天主要想要聊的,測試程式的撰寫方式不夠有彈性,例如:當程式碼重構時,雖然商業邏輯沒有改動,但是由於實作測試的方式不夠有彈性,導致測試失敗。接下來我們可以來聊聊,怎樣寫測試能更有彈性,讓測試在不調整商業邏輯的狀況下,盡量減少失敗的狀況。這在重構、以及減少維護測試成本這些面向來說,是很重要的。
前端在寫測試程式時,不外乎是要寫這幾種測試:
- 測試做資料計算、轉換的 utils
- 測試元件的顯示和行為是否正確
關於測試做資料計算、轉換的 utils 這個大家應該都沒有什麼問題,就是驗證輸入和輸出是否正確。
最讓前端感到困擾的,是在驗證元件的顯示這件事情上。舉例來說,前端的畫面往往會因為需求變更、加入或是移除功能而有變化,這樣我們要怎麼有效確定畫面的顯示是不是正確的呢?
7

前端開發者在實作測試的時候,往往會遇到一個問題,一但畫面有更新,測試就會失敗,必須做相對應的調整。修改的頻率太高,或是調整的範圍太大,就很耗時耗力。為了節省成本,能不能減少調整的頻率或範圍呢?
大多時候,因為 UI 更新而輕易失敗的測試,在這裡我先幫大家歸納兩個原因:
- 選取元素的方式太過鬆散、嚴謹或意義不夠明確。
- 測試包含過多實作細節。
接下來將分別說明這幾個方向,並且提供解決方案。
8

首先,來看「選取元素的方式太過鬆散、嚴謹或意義不夠明確」這個問題。
9

關於選取元素的方式太過鬆散的問題,舉例來說,如這張投影片的程式碼所示,針對元件 <Hello> 該怎麼測試「測試文字」這段字串是正確的呢?
試試看直接選取文字來測試好了。
在這段程式碼中,是利用 React Testing Library 實作的,那就利用 React Testing Library 提供的 render 方法來做 full rendering (完全渲染) <Hello> 元件,然後使用 getByText 方法根據預期的文字內容取得對應的 DOM element,再利用 textContent 取得實際的文字內容,最後使用斷言 expect 檢視是否等於預期字串「測試文字」。
到這裡都滿合理的,也很直覺,沒什麼問題。
在探討選取元素的方式太過鬆散的問題之前,我們可以看到在這裡使用 textContent 取得文字內容,這並不是一個很好的方法,因為比起使用 RTL 本身提供的 toHaveTextContent 來斷言 DOM element 的文字內容是否符合預期,toHaveTextContent 能提供更清晰的報錯、更語義化與可讀性的方式來驗證元素的文字內容是否符合預期。而我在這裡會展示這樣的寫法,是為了跟大家強調這不是很好的作法。
我個人的建議是,如果 framework 或是 library 有提供相對應的工具,就用他們提供的工具就好,並且讓團隊都 follow 這樣的作法,這是一個團隊合作的方法,可以讓 codebase 更一致,也能減少維護的成本,好處很多。
繼續來看這個範例,這樣選取元素的方式,會產生什麼問題呢?
10

本來我們想要檢測是否為「測試文字」,有一天需求變更,檢測的字串,改為「不是測試文字」,這樣就必須改兩個地方「要選擇的元素」與「要比對的字串」,改兩個地方就有點麻煩,而且沒有考慮到多個元件而會選到多個元素等等的問題,所以就不是理想的實作方式,那我們要怎麼調整比較好呢?
等等我們就會用另一種方式來選取元素,就不是用文字來選元素了,就可以避免這種問題。
11

在使用文字來選取元素方面,剛剛提到沒有考慮選到多個元素的問題,我們來看個例子,當元件 <Hello> 含有兩段「測試文字」的字串在畫面上時,我們原本預期只會有一段這樣的文字,然而使用 getByText 只能用來選取一個元素,現在由於會選到兩個元素,測試就會出錯。
當然你也可以改用 getAllBy 來解決選取多個元素的問題,但在這裡我想表達的是藉由改善選取元素的規則讓我們的測試能寫得更有彈性這件事情。
因此,當使用的選取元素的方式太過鬆散,像這樣用文字來選取元素的方式,一但遇到畫面可能有多個同樣字串的元素,就會無法辨識唯一性,導致測試失敗。
12

接著,來看選取元素的方式太過嚴謹的問題。
有一個很常見的例子是使用 XPath 來做選取。XPath 是一種用在 XML 文件中定位節點的語言,它透過路徑來描述節點的位置。也就是說,為了選取特定元素,它會仔細描述所有經過的 DOM 結構。
舉例來說,利用 XPath /div/div 來選取包含文字「測試文字」元素。
13

如果我們要更新元件使用的標籤,像是由 <div> 改為 <p>,那麼 XPath 選取路徑就要改成 /div/p 了,這種需求在重構、調整元件結構時很常見,這樣就是選取元素的方式太過嚴謹而導致不必要的測試失敗。
利用 XPath 來選取元件的方式是很死板的,更改 HTML 結構就必須重新撰寫選取元素的規則,非常沒有彈性,非常不建議使用,很浪費維護成本。
14

如果是用 class name 來選取元素呢?像是利用 selector .text?
由於 class name 通常與樣式相關,當它們與測試混合使用時,可能會在修改畫面時,不小心修改了 class name,而導致測試失敗。例如,本來是用 .text 同時來實作樣式和選取元素作為測試用,但是後來修改了 class name 為 .content,這樣測試就會失敗。
在混用的狀況下,開發者必須花費時間仔細檢查程式碼,仔細檢查這個 class name 是用於樣式還是用於測試,耗時費力。因此,建議選取元素的方式應該要明確定義出來,不要混用,像是稍等會提到的 data-* attribute。
15

在選取元素時,由於 data-* attribute(像是 data-test-id)是可以額外命名來專門提供給測試用的,就能保有專注性;並且,由於選取元素方式與 HTML 結構無關,就能更有彈性。這樣的解法就可以同時解決前面提到的選取元素的方式太過鬆散、嚴謹或意義不明的問題,是最為推薦的作法。
16

我們來修改前面提到的例子,在這裡可以看到,我們改用 data-test-id 為 'text' 來選擇特定元素,所以之後不論結構或樣式怎麼修改,這個測試屬性 data-test-id 只要是 text,都是提供給這個元素來取得文字內容或相關操作的,不會出現選元素的規則太過嚴格、鬆散或意義不明的問題。也就是說,只要 data-test-id 不變,都可以正確取值和對這個元素進行操作,測試不會輕易失敗。
17

看完「選取元素的方式太過鬆散、嚴謹或意義不夠明確」,在調整 UI 時會造成測試輕易失敗的原因,還有一個議題可以來討論,就是測試「包含過多實作細節」這個議題。
18

我們在做測試時,會遇到需要用模擬來取代真實的實作細節的狀況,以確保測試的程式碼和其依賴的物件能正確互動。然而,當功能有變更時,這段測試用的程式碼也是需要更新的,如果沒有更新,測試就會失敗。
在這個投影片中,上方是 mock,下方是原本的實作的細節。
因此,在測試程式中,只要遇到 <Hello> 元件,就會以上方的 mock 取代真實的實作細節。
我們在寫測試程式的時候,如投影片左邊所示,原本預期比對字串 Hello World 是否正確,我們同樣在 mock 上面也是這樣寫;但是有一天需求變更,字串改為 Hi,如投影片右邊所示,而測試程式也變成確認文字是否為 Hi,但我們卻忘了同時修改 mock 的元件,這時候測試就會失敗。
因此,在使用模擬的時候,在實作測試程式上就要很小心,過多的模擬可能會造成幾個問題:
- 有可能在測試時,模擬與事實是不同的,而我們卻沒有注意到而做修改,如果失敗了我們還可以調整測試程式,但是如果測試就這樣通過了,之後上線後就無法確保在真實的狀況下是否正確運作。
- 對維護上來說,很難同時維護真實與模擬兩份程式碼,必須依賴人工檢測與修改,應該要盡量消除這種人為的疏失。
在模擬的使用上,我的原則是,若非必要,測試應盡量真實,減少模擬取代真實狀況、不要使用過假的資料、元件盡量渲染完全,這樣才能達到測試的彈性、減少不必要的維護,以及對功能進行更全面的測試,確保整合的元件能夠正確運作,並在實際操作環境中達到預期的結果**。
19

在測試包含過多實作細節這個面向上,還有一個值得探討的是「快照」。
快照常用的作法是將整個頁面截圖,或是將元件截圖,或是以 XML 文字格式的方式紀錄元件結構和屬性。快照是一個很方便可以驗證實作是否如預期的方式,因為它可以用一張圖或是一個檔案記錄該範圍內的所有細節,然後我們就去比對這所有的細節是否正確即可。
根據我的實際觀察和實作經驗,快照會被誤用的情境大多是功能很難寫測試,可能是很難 mock 假資料,或是沒辦法重構,所以索性直接將整個頁面或元件做快照,反正只要有任何一點點的不一樣,報錯就對了,然後再找人來檢查是哪裡出錯。 這裡的問題是,這樣的報錯只能跟我們說有錯,可是哪裡有錯、錯的理由是什麼、該怎麼改正,是沒辦法告訴我們的,我們要再花時間去細究原因和修正,耗時費力。
也因為快照會記錄所有的實作細節,在測試上,不是每個細節我們都想要做確認,但有不同就會讓測試失敗,舉例來說,這張投影片的快照是一個圖片列表 <ImageList> 元件的快照,包含這個元件的所有實作細節,也就是 DOM 結構,在這個元件上,我們主要會想確定圖片是否正常顯示、文字是否正常顯示,但是對於怎麼實作,像是剛剛提到的實作細節,我們並不會太關心,畢竟重構不改商業邏輯。但是一但有些微的調整,測試也要跟著調整,這樣的測試就不夠有彈性,反而會造成開發上的負擔。
舉例來說,用快照確認的狀況下,實作細節都會被記錄下來而做比較的,像是新增 class name 或更新 data-* attribute 等細微的變更,都將導致測試失敗,而修正測試是需要花時間和心力成本的。因此,除非真的是要比較細節,不然我的建議是可以利用 shallow rendering 做快照,來檢視 layout 是否正確,但是不要用 full rendering 做快照來比對細節。
20

在測試包含過多實作細節這個面向上,最後一個要探討的是怎麼抓取比對的元素,這個議題也是很類似快照的。
在抓取要比對的元素時,我們往往是抓整到 DOM element 再取其值,例如在這個例子中,getByTestId('item-quantity') 會得到完整的 HTML 結構。
<div data-test-id="item-quantity">2</div>
此時為了比對這個元素的內容,我們可以選用 getByTestId 搭配 toBe 或 toHaveTextContent 來取值,兩種方法都可以達成比對的目標,但是選哪個比較好呢?
在左邊這段程式碼 expect(getByTestId('item-quantity')).toHaveTextContent('2') 會比對從 DOM element 中取得的字串 2,只要 data-test-id 不變,都可以正確取值,測試不會失敗。
然而,在右邊這段程式碼 expect(getByTestId('item-quantity')).toBe('2') 會比對從 DOM element 取得實作的 HTML 細節 <div>2</div>,這在 HTML 結構有變更就會測試失敗。因此,選用 toHaveTextContent 取得文字,是較有彈性的,是為推薦的作法。
不過,開發者可以根據不同情境找出最適合的測試方式,並且在撰寫測試時,適當地選擇要比對多少細節,就能讓測試更有彈性。
21

前面提到的是怎麼寫 code,我們把眼光稍微放遠一點,範圍擴大一點,接下來我想聊的是怎麼設計元件,或是說怎麼拆分功能,才能將測試的戰力發揮到滿點。
很多時候我們的元件是包山包海的,裡面包含商業邏輯、計算、畫面顯示、各種行為操作,導致要測試這個元件是很不容易的,可能要 mock 的東西很多,或是有些東西沒有 export 出來要改成 export 出來才能測試,或是專案的其他地方也有類似的邏輯,同樣的測試要寫好幾份等等問題。
這會導致我們的元件很難寫測試,或是寫不了測試,或是類似的測試要重覆寫,要解決這些問題,首先要先整理程式碼,我的原則會是讓元件依照邏輯與畫面拆分成不同的檔案:
- 將商業邏輯與資料狀態封裝在 custom hook。
- 將資料運算放在 utils。
- 元件只留下畫面顯示用的部份。
之後就依照檔案的內容來決定怎麼寫測試,這樣就能達成更好測試的效果。
22
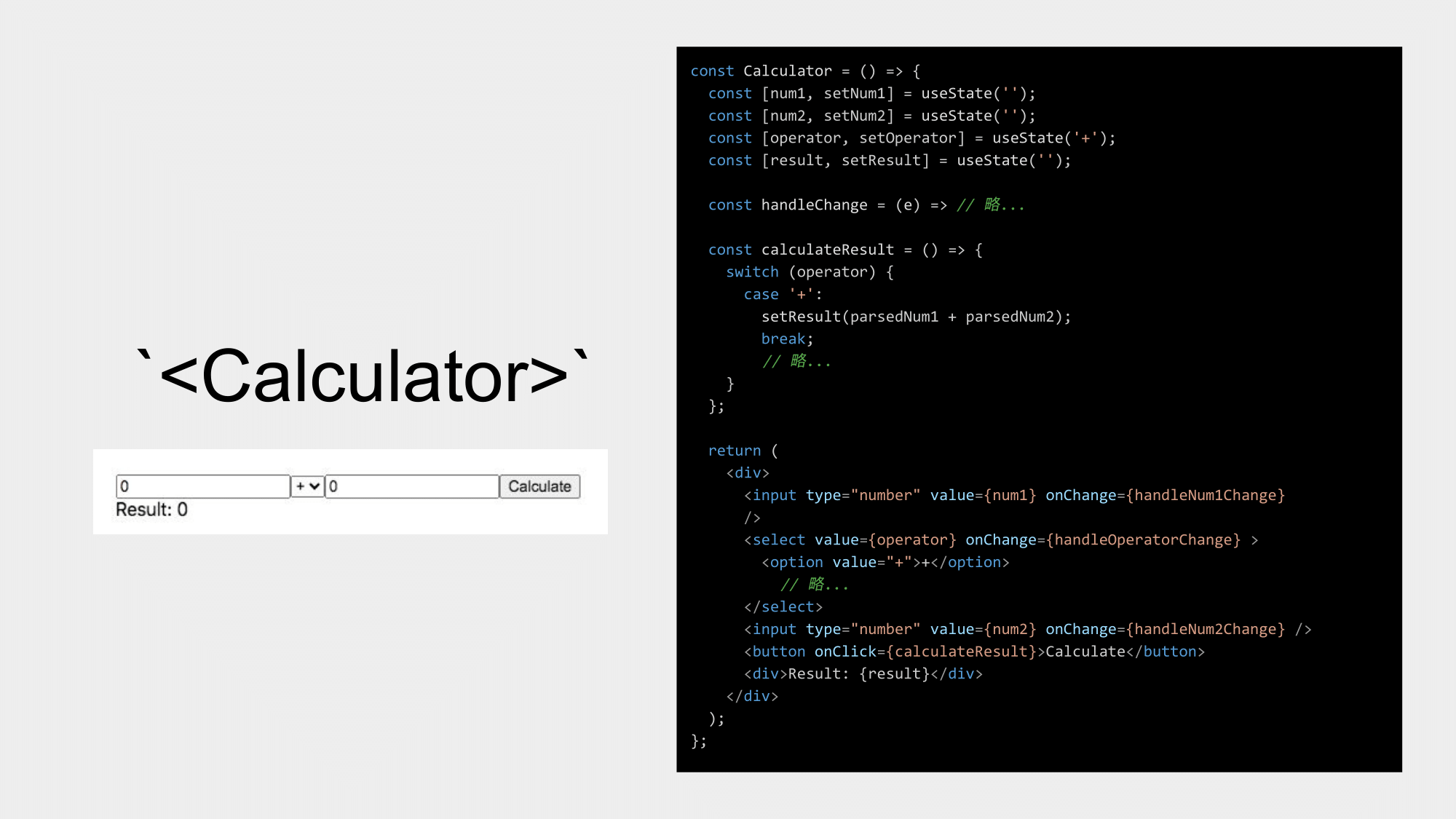
舉例來說,這裡有個計算機元件 <Calculator>,包含兩個輸入框用於輸入數字、一個下拉選單用於選擇加減乘除運算符號,以及一個用於執行計算的按鈕。
程式簡單說明一下:
- 首先會利用
useStatehook 儲存使用者輸入的數字和運算符號。 - 再來,定義
handleChange函式處理輸入框和下拉選單的變化。 - 還有,定義
calculateResult函式來計算兩個數字的結果。 - 最後,將輸入框、下拉選單、計算按鈕和顯示結果的元素顯示出來。
- 在這裡設定對應的
data-test-id測試屬性,以便於測試時定位元素。
在這裡我們可以看到,雖然這個元件很簡單,可是有幾個問題,我們先以 calculateResult 這個函式來說明看看:
- 邏輯沒辦法重用,例如:專案其他地方可能也會用到
calculateResult這個函式來做計算,但是現在就是限制在元件<Calculator>裡面,那麼類似的測試也就是要重覆寫。calculateResult包在元件裡面,我們沒辦法完整測到所有情境,最多就是利用 RTL 模擬使用者的操作行為來寫測試。這裡就是要取捨我們想要做元件的整合測試就好,還是這個計算邏輯我們想廣泛用- 在專案其他地方,是否需要考慮更多 case,在考量成本與重用的狀況下,要思考一個目前專案最適合的決定。
接著,我們就來重構這個元件,試著讓它的邏輯能重用,也能更好測試。
23

現在我們將 <Calculator> 元件重構,分為三部份:
- 第一部份,將運算放在 utils。
- 第二部份,將商業邏輯與資料狀態封裝在 custom hook。
- 第三部份,元件只留下畫面顯示用的部份。
稍等我們會根據這三部份分別來寫測試。
首先,第一部份,將做資料運算的 calculate 放在 utils,通常在一個剛起步寫測試的專案,或是沒時間寫測試,或是專案亂到很難寫測試,這是我會最開始著手的部份,就是試著把最重要的邏輯、或是獨立的跟元件沒有太大關係、或是最能重用在專案其他地方的東西抽出來寫測試,這會對重構專案的壓力最小、最容易實作、也能看到最立即的保護。
24

接著,我們幫 calculate 來寫測試,通常這種跟商業邏輯無關的 utils 就交給 AI 來寫就好了,ChatGPT 或是 Claude 都可以在三秒內幫你把測試寫完。
因此,在專案當中,把這些重要邏輯、獨立、能重用的部份抽出來寫測試,除了剛剛提到的幾個優點,像是對重構專案的壓力最小、最容易實作、也能看到最立即的保護,我認為另一個很大的優點是,AI 這些工具能快速實作,節省我們工程師的成本,非常推薦。
25

接著來看第二部份,將商業邏輯與資料狀態封裝在 custom hook。
除了資料運算之外,常見的重複的程式碼即是類似的商業邏輯、資料狀態與操作行為,那麼我們可以將這些重覆的邏輯或行為抽出來,除了方便共用、節省開發成本之外,測試也不用重複寫,更能節省工程師的時間。
在這裡實作一個 useCalculator 的 custom hook 來幫我們處理共用的商業邏輯與資料狀態,同樣我們也可以請 AI 幫忙寫測試。
26

再來,我們幫 useCalculator 這個 custom hook 來寫測試,同樣也是可以請 AI 來幫我們寫測試,這裡可以看到,一但我們把程式碼重構好、切小,寫測試就變得相對容易很多了。
在探討 AI 怎麼幫我們寫測試這件事情上,我可以提供兩個方案:
- 第一個是把自己實作的程式碼丟給 AI,請它幫忙實作測試程。
- 或是,第二個方式,是在實作之前,例如我們在寫 design document 時,會畫流程圖,我們就可以將這個流程圖的 UML 程式碼丟給 AI,請它幫忙實作功能,以及測試程式。
這兩個方案都能盡量的幫我們省時省力。
27

最後是第三部份,元件只留下畫面顯示用的部份,重構 <Calculator> 元件程式碼如這張投影片所示,<Calculator> 元件只專注於畫面顯示的部份,這樣就能夠更易於理解、測試和維護。
28

最後,我們來幫元件寫測試。
通常在顯示用的元件上,我們可以寫測試來模擬使用者的操作行為,也就是驗證當使用者輸入兩個數字、選擇運算符號、按下取得結果的按鈕時,確認顯示的結果是否合乎預期。
這樣的測試與剛才我們驗證共用的 utils 和 custom hook 是不同的,在這裡是做元件的整合測試,整合了三個不同的部份,而且也會測試使用者真正在使用下是否能正確的操作。
剛剛提到也許我們會有重複測試的問題,我認為這些重複的測試給予的提示訊息和測試的顆粒度是不同的,如果資源允許,有重複的測試可以給予不同的保護;但如果資源緊迫,優先做整合測試會是一個不錯的方法。
29
以上是第一部份,在寫測試程式上,怎麼寫出適應變更、有彈性的測試程式的分享。
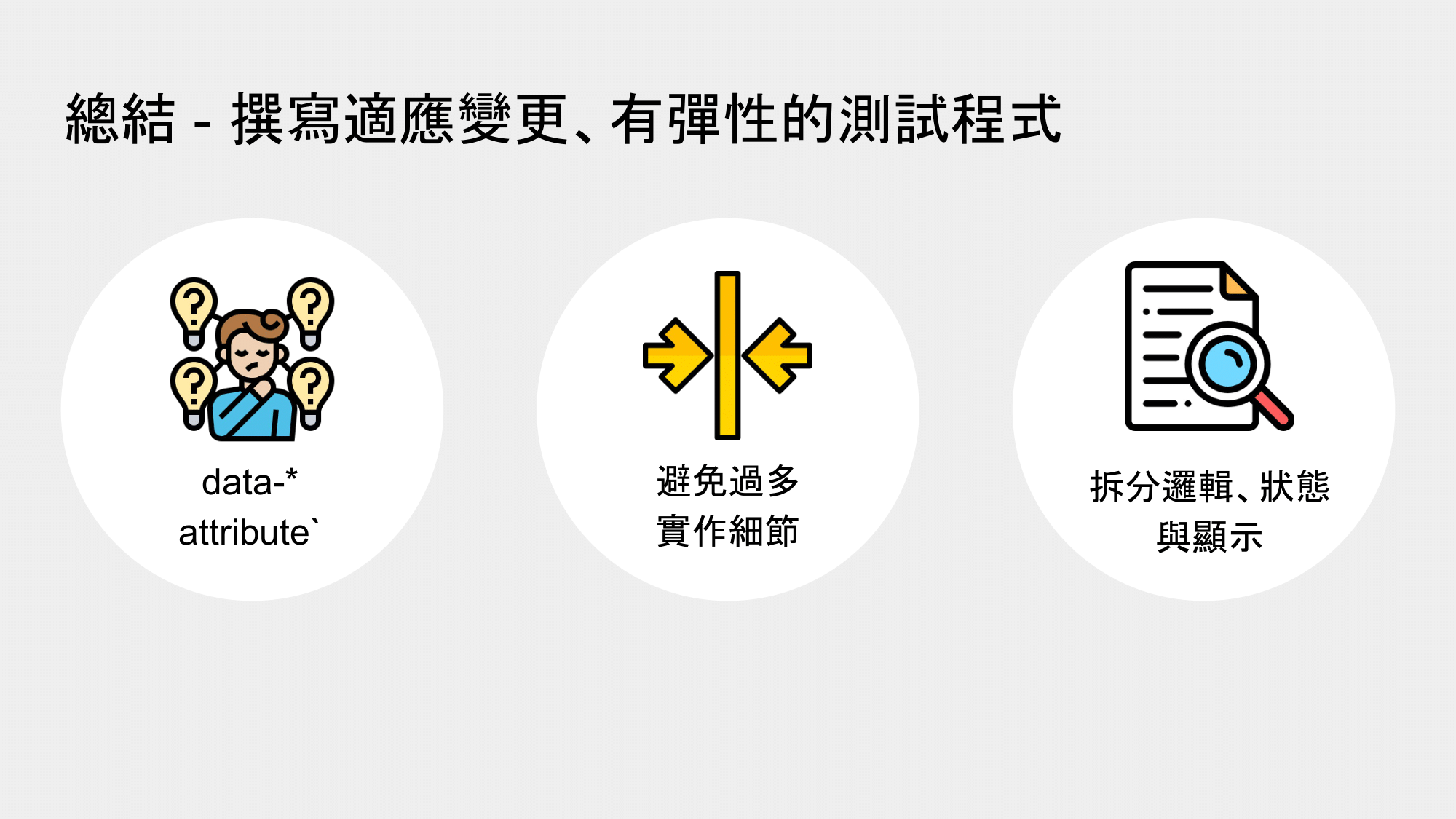
總結來說,在寫測試程式上,若希望減少 UI 一更新測試就失敗的問題,建議以這些原則來實作測試程式:
- 第一,選取元素用
data-* attribute以保有專注性與彈性。 - 第二,測試避免包含過多實作細節,例如:減少模擬、減少使用快照記錄實作細節、避免選用會比對細節方法或技巧。
- 第三,拆分邏輯、狀態與畫面顯示,簡化測試範圍,提高測試的效率。
這樣就能更為節省維護測試的成本,省時省力。
30

以上這些內容都可以在我今年出的書「前端測試指南:策略與實踐」裡面看到,書裡面也會有更多細節。書裡面有一個章節專門在探討「UI 一更新測試就失敗,該怎麼辦?」,如果對前端測試或是這個主題有興趣,歡迎找來看!
在這裡也跟大家說一個好消息,這本書已經跟美國的書商 Apress 簽約,明年二月,也就是過年後,會出版英文版,會在全球銷售。(備註:原本已出版英文版電子版@Leanpub;英文版紙本與電子書後來皆委託美國書商出版,預計 2025 年 2 月上市。)
31

看完怎麼寫程式之後,接下來要看的是,在設計測試架構上,怎樣才能做到花最少的成本,但是能達到最好的保護效果?
我們首先來看一個例子,然後再來談談我怎麼決定要做哪些類型的測試,來達成最好的保護效果。
32
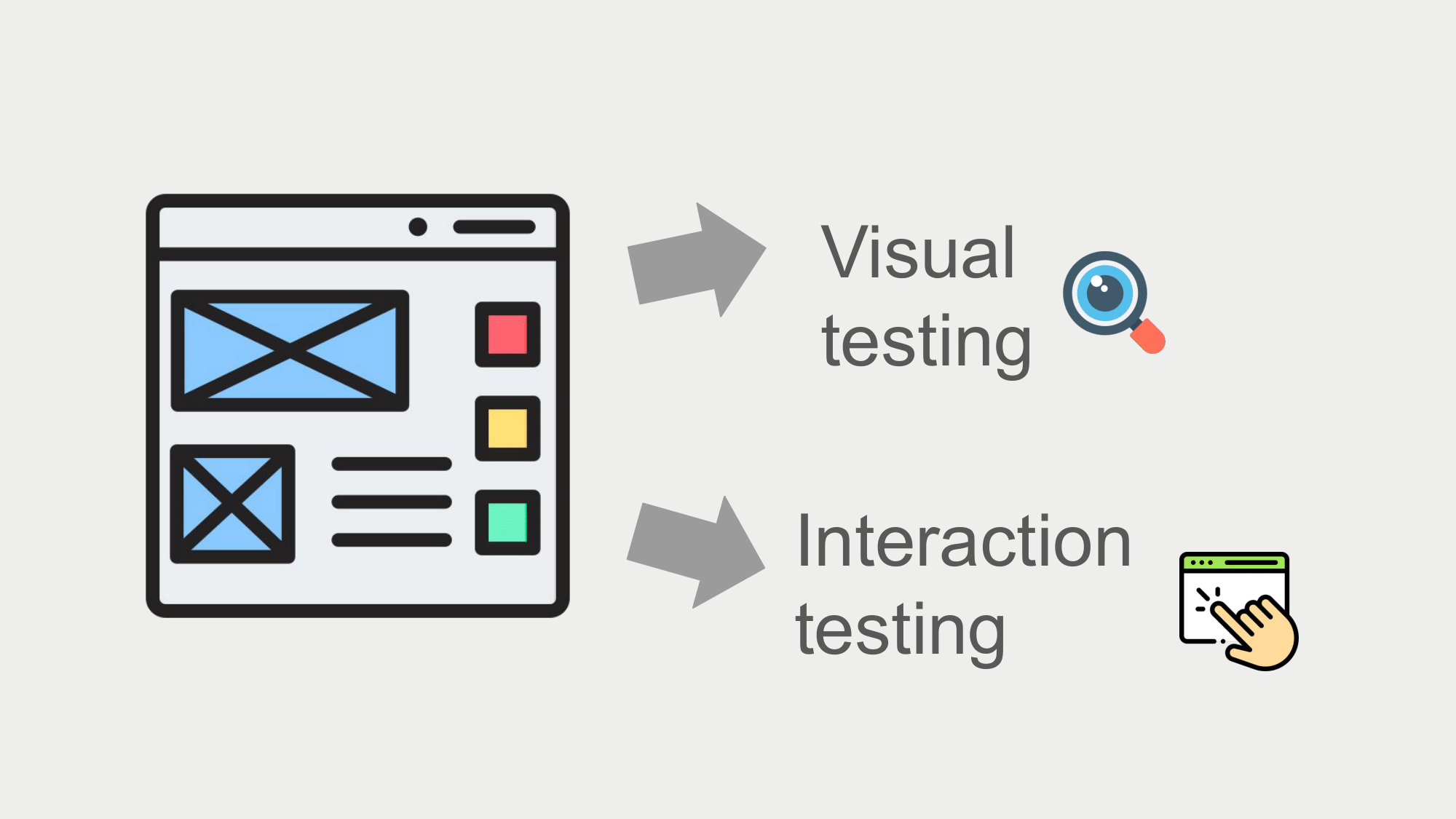
事情是這樣的…大家可能知道我今年換到一間新公司,這間公司有自己實作滿多基礎建設的,其中一個是我們有 UI library,UI library 要怎麼測試呢?這個絕對是一個不簡單的議題。
我們可以分幾個方面來討論,來決定要用什麼策略來保護我們的 UI library。
UI 充滿顏色、狀態還有行為,所以…
- 為了保護狀態與顏色的一制性,我們需要 visual testing 來做比對,在這裡由於是保護 UI library,UI library 會有 storybook 作為各種狀態與顏色的展示,因此我們會希望借助 story 來產生各種狀態組合的快照,來做比對。
- 再來,我們希望能確保 UI 互動正確性,像是 click、hover 等操作後的顯示,這個就會需要做到 behavior testing / interaction testing 來幫我們做檢驗。
關於為了保護狀態與顏色的一制性,在先前我曾經用過一些服務來幫我做 visual testing,像是 Percy、Chromatic 等,這些工具很好用,但也有其各自的限制,當然最大的限制就是錢,還有與現有工作流程搭配的彈性,關於 visual testing 的探討可以參考之前我的分享,在這裡由於這些服務的限制,讓我去決定要自己純手工打造一個 visual testing 的工具。
關於確保 UI 互動正確性,我們利用 RTL 來幫忙檢視,但在有限資源的狀況下,首先會做 visual testing,接著如果是無法用 visual testing 檢測的,並且可能會造成重大影響的問題,就利用 interaction testing 來處理。
以上這些就是我怎麼幫我們的 UI library 設計測試架構的想法。
33
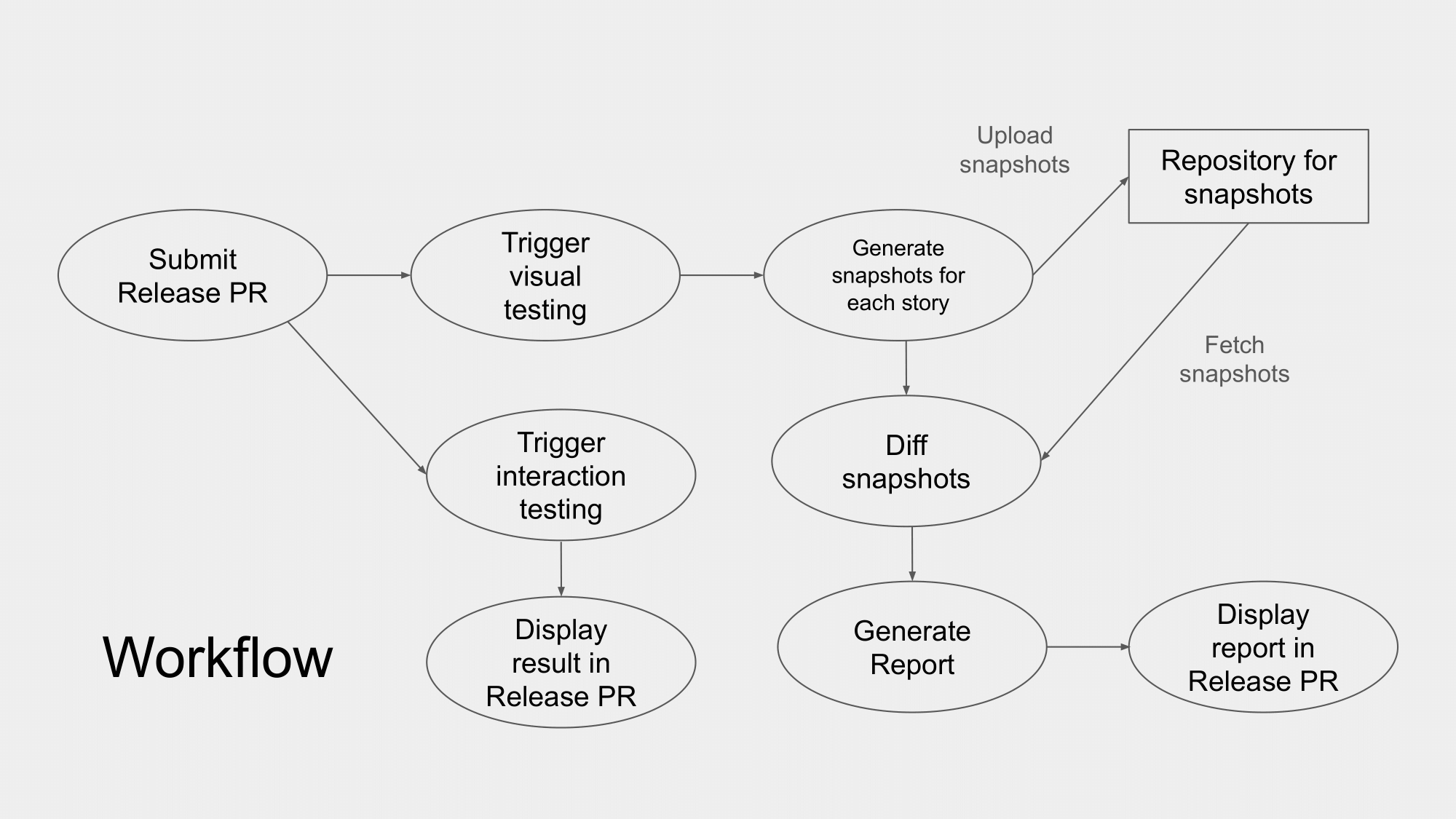
我們的工作流程會是怎樣呢?這張圖顯示我們測試的主流程架構。
我們每次修改 UI library 的任何 component 之後,在 merge main branch 並且決定要 release 時,在 submit release PR 時,會去 trigger 我們自己做的 visual testing 的服務,然後會依據有變更的 story 來產生快照,產生快照之後,我們會與前一次 release 的快照做比對,有差異的快照我們會挑出來,放在 report 裡面,這個 report 我們會貼在 release PR 裡面,讓 reviewer 來檢視變更是否如預期。visual testing 完成後,我們也會在 slack channel 通知 reviewer 來做 review。
同時,我們也會觸發 interaction testing,執行的結果也會顯示在 Release PR 上。
這樣的工作流程與機制,就能確保狀態與顏色的一致性,以及 UI 互動的正確性,完整的保護我們 UI library。
不過坦白說這樣的方式很難去計算覆蓋率,所以我會推薦使用「使用案例的覆蓋率」 (use case coverage) 而非傳統上常用的程式碼的覆蓋率,也就是根據使用情境來推算我們需要寫的測試量,以及我們到底實際完成多少測試。這樣的好處就是一定會測試使用者有用到的情境,不浪費資源。
34
在這個例子當中,我怎麼決定要如何設計保護力佳的測試架構呢?
我的想法是,觀察專案的特性和需求,來配置適合的解決方案,我會切分為三個方面來看:
- 需要比對視覺的,就會需要用到 visual testing,可以做 page-level 或是 component-level 的視覺比對。如果是 UI library 或是專案的共用元件,就用搭配 storybook 來做 component-level 的 visual testing;如果是專案個別頁面,就用 page-level 的 visual testing。由於我們的專案大多數是由元件堆疊而成,所以我會建議以 component-level 的 visual testing 優先實作。
- 除了視覺比對,在多國語系上,visual testing 也能幫助我們做初步的檢查的。
- 需要比對操作行為的,也就是使用者怎麼使用我們的產品的,就會需要用到 e2e testing 或 intergration testing,以範圍來說,如果是驗證商業邏輯是否正確,就是使用 e2e testing 並且以完整跑完整個功能為主,如果是驗證非商業邏輯、像是元件的行為,就是使用 intergration testing 並且會是元件與元件之間的整合為主。常用的 Cypress、Playwright 和 RTL 都是很好用的框架。
- 為什麼我沒有提到 unit tesitng 呢?因為在目前前端主流的測試裡面,unit testing 其實就是元件的測試,而我們不太可能只針對一個小元件來做測試,大多時候是多個元件一起寫測試,那這樣就是元件的 intergration testing,這在我們用 RTL 來實作的時候是很常見的用法。
- 需要比對計算結果的,像是 utils,要考量的就是成本,這會先牽涉到重複測試的議題,它可以包含在視覺或操作行為裡面,或是單獨抽出來測試,都是沒有問題的。在我的想法裡面,重複測試是好的,因為測試的顆粒度和給予的提示訊息是不同的,就看我們可以花多少人力時間等資源來寫這些測試。
35

最後跟大家分享我在設計這個架構時,兩個小小的感想
- 第一個是觀念的澄清,在過去的專案當中,我們寫測試大多是重視互動行為,很少在注重視覺,我在做內部的分享和討論時,其實在我的內心一開始是覺得 visual testing 其實是很邪門歪道的,應該是著重在行為上的測試,後來我花了點時間去了解我們常見的問題,很多時候都不是靠驗證互動可以檢查到的,而是要真的去驗證視覺得部分,所以突破內心的框架和既定印象是一個門檻。而當我們使用這樣的 visual testing 的時候,會發現有這樣的測試方式,是可以幫我們減輕許多負擔的。
- 第二個是怎麼融合在既有的工作流程是很重要的,我們實作這樣的機制的前後,在公司開了好幾次討論的會議來決定要怎麼做,還有 sharing 來跟大家分享這是什麼、怎麼使用、能達到什麼好處、通知的機制、蒐集回饋和改進。東西不是產出來就好,我們是真的希望能用在日常工作當中,而且是好用的。在過去推行失敗的經驗裡,這次能夠成功,有很大的原因是我們找到了一個真的能搭配工作流程的機制。再怎麼酷炫的東西,如果不能配合組織的工作流程,都不能對專案有幫助,這是我滿大的體悟。
36

關於我們手工自己刻一個 visual testing 的工具,這次我有一個小團隊幫忙實作,在這裡特別感謝我們家的 Max & Taylor!
37

以上是我的分享,感謝大家!
")
")

")